transformers architecture

https://arxiv.org/pdf/1706.03762
https://zhuanlan.zhihu.com/p/82312421
https://www.youtube.com/watch?v=wjZofJX0v4M

1. embedding层
embedding
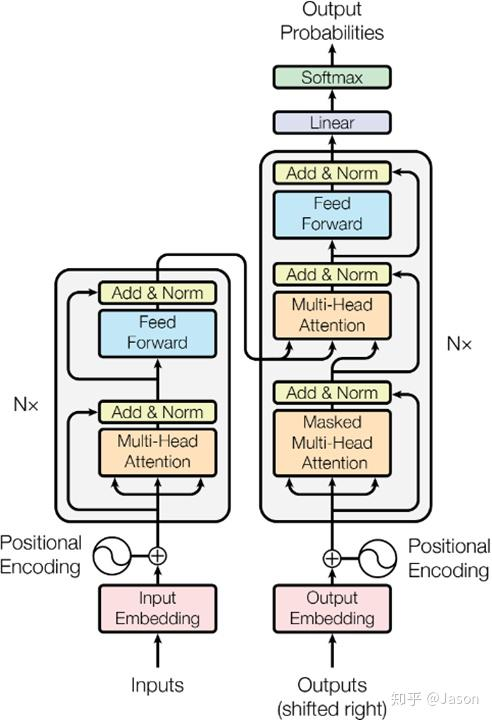
主要将词表表达为vector并映射到高维词表空间,对于英文来说有大概5k+左右的向量,除了表示token的含义之外,还通过位置编码将token在context的位置也包含了进去,将位置编码进去的主要目的是为了可以并行计算不会像RNN网络一样存在前后依赖,可以最大化并行利用好gpu的效率
一个模型通常包含多个Transformer block,一个Tranformer block通常包含两个组件,第一个是attention层,主要是计算得到sequence中token之间的上下文关系,紧随attention之后的sub layer就是MLP(多层感知机),也叫前馈网络, 都是全连接层,
In Transformer models, the Multi-Layer Perceptron (MLP) is a crucial component located within each Transformer block, also known as a Transformer layer. Each Transformer block comprises two primary sub-layers:
-
Multi-Head Self-Attention Mechanism: This sub-layer enables the model to weigh and integrate information from different positions within the input sequence, capturing contextual relationships between tokens.
-
MLP Sub-Layer: Following the attention mechanism, the MLP sub-layer processes the output to introduce non-linearity and enhance the model’s capacity to learn complex patterns.
The MLP sub-layer typically consists of two linear transformations separated by a non-linear activation function, often the Rectified Linear Unit (ReLU). The first linear transformation expands the dimensionality of the input (often referred to as the hidden size), while the second projects it back to the original dimensionality. This dimensionality expansion allows the model to capture intricate patterns and interactions within the data.
To maintain stability during training and ensure effective gradient flow, each sub-layer in the Transformer block is equipped with a residual (or skip) connection and is followed by layer normalization. The residual connection helps in mitigating issues like the vanishing gradient problem by allowing gradients to flow more directly through the network.
In summary, within a Transformer model, the MLP sub-layer is positioned after the multi-head self-attention mechanism in each Transformer block. Its primary function is to introduce non-linearity and enhance the model’s ability to learn complex representations, thereby contributing to the overall expressiveness and performance of the Transformer architecture.