tp dp and pp
#tp #pp
Understanding the concepts of TP (Tensor Parallelism), DP (Data Parallelism), and PP (Pipeline Parallelism) in the context of Megatron involves grasping different strategies and optimizations used for distributed training of large-scale deep learning models, particularly in the domain of natural language processing (NLP). Let's delve into each of these concepts:
1. Tensor Parallelism (TP)
-
Definition: Tensor Parallelism involves partitioning the model parameters (tensors) across multiple devices (e.g., GPUs) along the tensor dimension(s).
-
Purpose: TP aims to distribute the computations involved in neural network training across multiple devices by partitioning the model tensors. This allows for efficient utilization of compute resources and enables training of very large models that may not fit on a single device.
-
Implementation in Megatron:
- Megatron uses Tensor Parallelism to divide the model parameters (e.g., layers, embeddings) across different devices. This is typically achieved using specialized libraries (e.g., NCCL) for efficient communication and synchronization of tensors across devices.
2. Data Parallelism (DP)
-
Definition: Data Parallelism involves replicating the entire model on each device and splitting the input data (batches) across devices. Each device processes a different subset of the data in parallel during training.
-
Purpose: DP is used to scale up training by distributing the workload of processing large batches of data across multiple devices. This can lead to faster training times and increased throughput.
-
Implementation in Megatron:
- Megatron employs Data Parallelism by replicating the entire model on each device and dividing the input batches among the devices. Gradient updates are synchronized across devices to keep model parameters consistent during training.
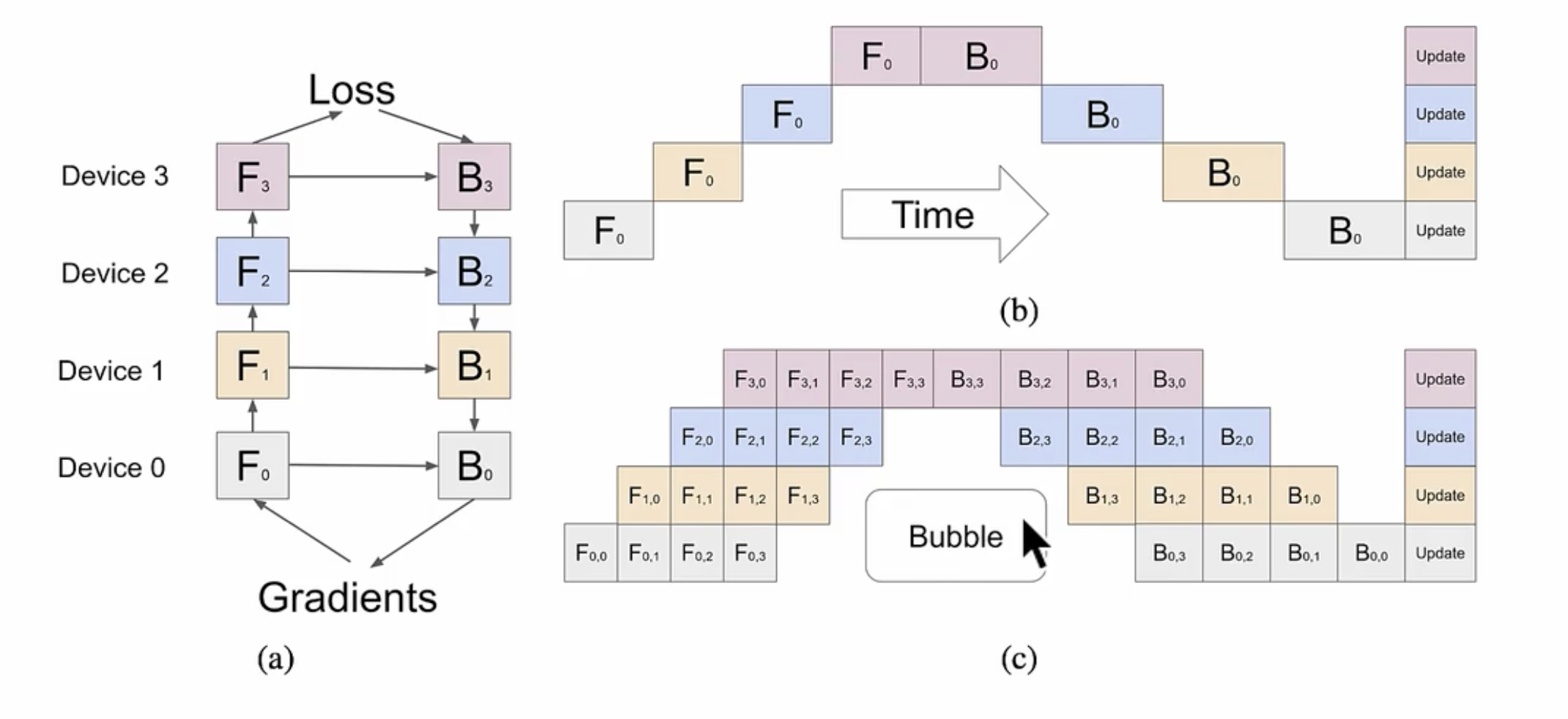
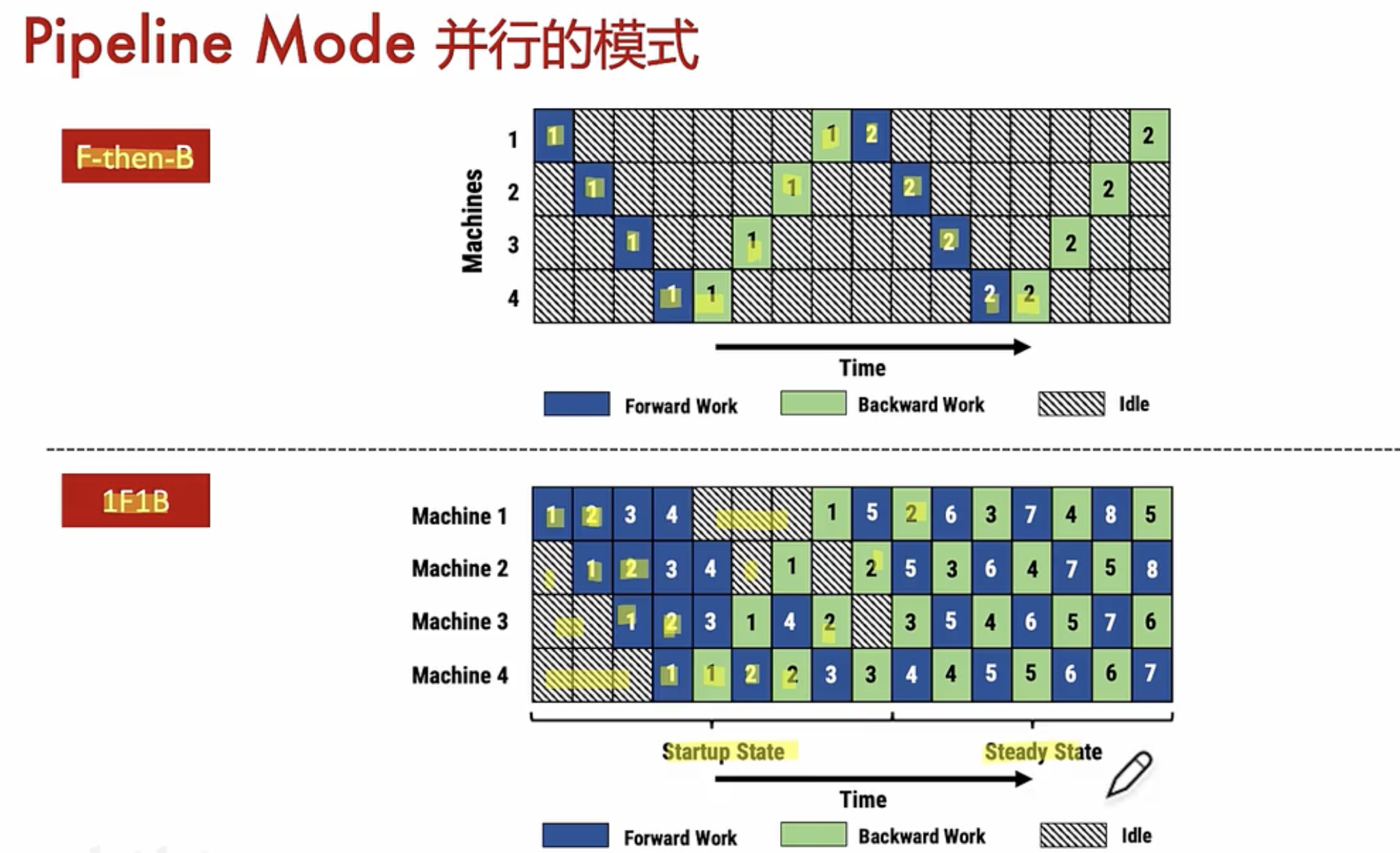
3. Pipeline Parallelism (PP)
-
Definition: Pipeline Parallelism involves dividing the computation of a neural network into stages (or layers) and executing these stages across different devices in a pipelined fashion.
-
Purpose: PP reduces memory consumption and increases the maximum model size that can be trained by overlapping computation and communication. It's particularly useful for models with large memory footprints.
-
Implementation in Megatron:
- Megatron can utilize Pipeline Parallelism by splitting a large model into segments (pipelines) and assigning each segment to different devices. Intermediate outputs are pipelined across stages, enabling efficient use of memory and compute resources.
Relationship between TP, DP, and PP in Megatron
-
Combined Strategy: In practice, Megatron often combines Tensor Parallelism (TP), Data Parallelism (DP), and Pipeline Parallelism (PP) to achieve efficient and scalable distributed training.
-
Example Usage: For instance, Megatron might use Tensor Parallelism to partition large model parameters across GPUs (TP), Data Parallelism to distribute training data batches across these GPUs (DP), and Pipeline Parallelism to overlap computation and communication within each pipeline segment.
-
Optimization: The choice and configuration of TP, DP, and PP strategies in Megatron depend on factors such as the model architecture, dataset size, and available hardware resources. Optimizing these strategies is crucial for achieving high-performance distributed training of large NLP models.
In summary, understanding TP, DP, and PP in Megatron involves recognizing how these parallelization techniques are leveraged to distribute model parameters, training data, and computations across multiple devices, thereby enabling efficient and scalable training of large deep learning models in the context of NLP tasks. Each strategy plays a critical role in optimizing performance and resource utilization during distributed training.
dp = world_size / tp / pp
pp并行原理