embedding
https://blog.csdn.net/qq_43391414/article/details/120783887
https://qiankunli.github.io/2022/03/02/embedding.html
https://allenwind.github.io/blog/8912/
https://stackoverflow.com/questions/55276504/different-methods-for-initializing-embedding-layer-weights-in-pytorch
embedding相当于一个简单的查找表,内容存储在属性weight中,该属性可以通过指定算法进行初始化,模型也可以训练更新weight,
embeddding的weight是一个torch.nn.Parameter类型,该类型是Tensor的子类,但具有torch.nn.Module的属性,这种类型的参数会参与模型梯度计算,在调用optimizer.step()的时候会自动更新
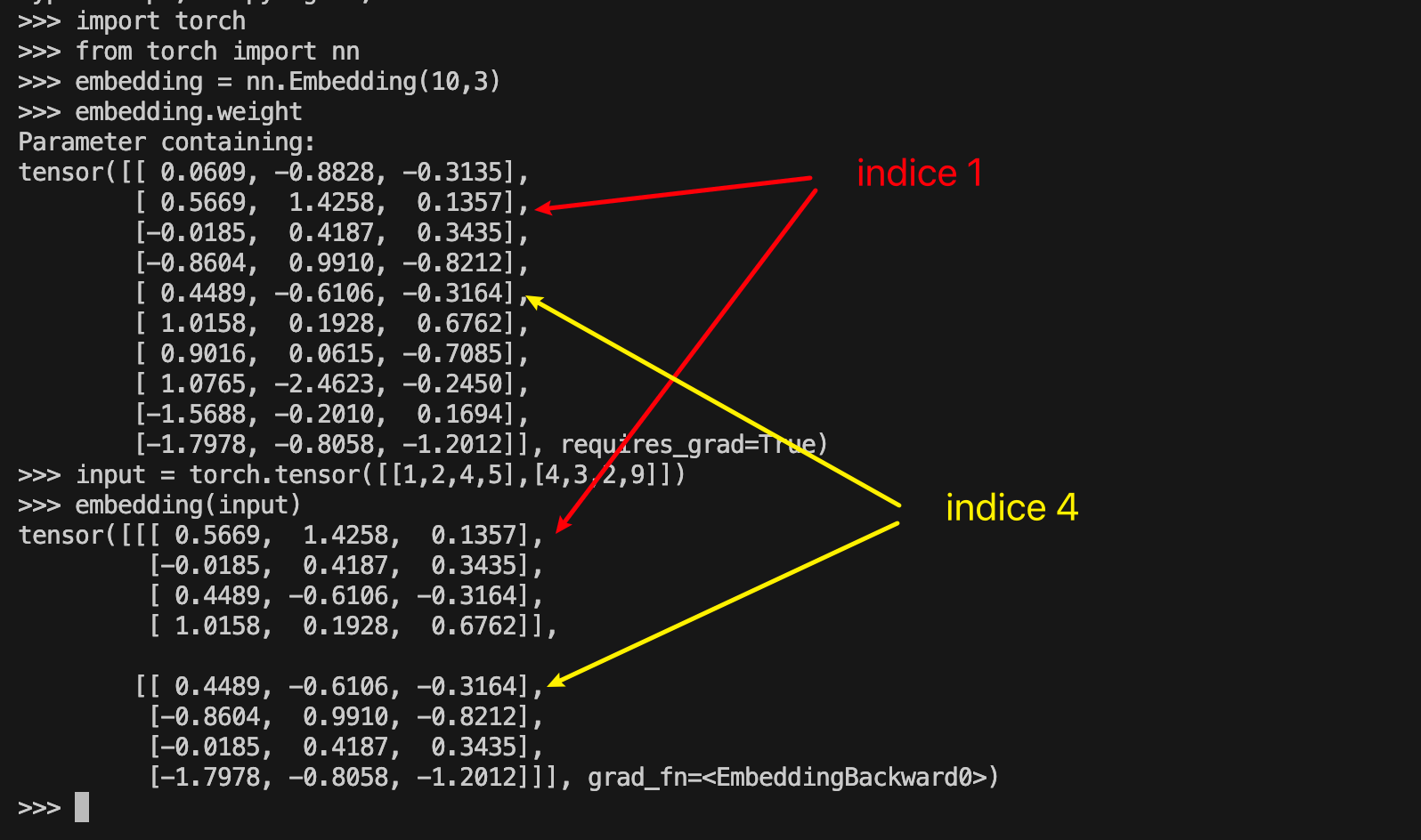
embedding的输入的每个数字相当于从weight中的具体的index,一个数字取出来的维度为(1, embedding_dim),其中embedding_dim就是每个embedding vector的长度
Embedding是通过lookup(比onehot和权重进行矩阵乘操作更高效)的方式将高维稀疏向量转化为稠密向量(比如king和queen在高维词表空间可能位置相近),这个稠密的向量用于下游网络的特征提取。
import torch
import torch.nn as nn
# 直接使用tensor的uniform方法
torch.manual_seed(3)
emb1 = nn.Embedding(5,5)
emb1.weight.data.uniform_(-1, 1)
# 使用nn的uniformer方法
torch.manual_seed(3)
emb2 = nn.Embedding(5,5)
nn.init.uniform_(emb2.weight, -1.0, 1.0)
# 两个初始化权重方法等价
assert torch.sum(torch.abs(emb1.weight.data - emb2.weight.data)).numpy() == 0
# embedding使用指定的张亮来初始化权重,freeze参数这里设置为True来将权重进行冻结,防止模型训练过程中更新embedding的权重
pretrain_embedding = torch.tensor([[1,2,3,4],[5,6,7,8]])
emb3 = nn.Embedding.from_pretained(pretrained_embedding, freeze = True)