yolov7_multipleinput
代码逻辑分析:
https://gitee.com/xu-xiaolong28/samples/tree/master/inference/modelInference/sampleYOLOV7MultiInput
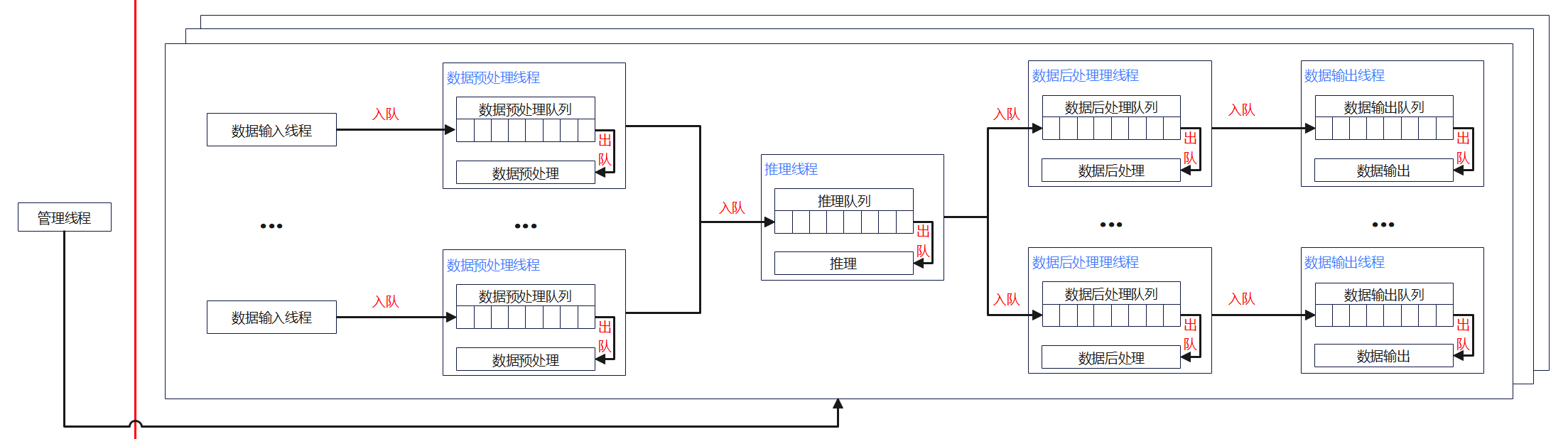
- 管理线程:将线程和队列打包在一起,并完成进程创建、消息队列创建、消息发送和消息接收守护。
- 数据输入线程:对输入图片或视频进行解码。读取一个batch的帧,解码成yuv格式的decodeimg和rgb格式的frame添加到detectDataMsg中并向后传递
- 数据预处理线程:对数据输入线程传过来的YUV图片进行处理(resize等操作)。将一个batch的数据按照om的规格resize到指定的modelwidth X modelheight存储到设备acl侧连续内存
- 推理线程:使用YOLOV7模型进行推理。
- 数据后处理线程:分析推理结果,输出框点及标签信息。
- 数据输出线程:将框点及标签信息标识到输出数据上。
配置文件参考:
{
"device_config":[
{
"device_id":0,
"model_config":[
{
"infer_thread_name":"infer_thread_0",
"model_path":"../model/yolov7x.om",
"model_width":640,
"model_heigth":640,
"model_batch": 1,
"postnum": 4,
"io_info":[
{
"input_path":"../data/car0.mp4",
"input_type":"video",
"output_path":"../out/output",
"output_type":"pic",
"channel_id":0
},
{
"input_path":"../data/car0.mp4",
"input_type":"video",
"output_path":"../out/output",
"output_type":"pic",
"channel_id":1
},
{
"input_path":"../data/car0.mp4",
"input_type":"video",
"output_path":"../out/output",
"output_type":"pic",
"channel_id":2
},
{
"input_path":"../data/car0.mp4",
"input_type":"video",
"output_path":"../out/output",
"output_type":"pic",
"channel_id":3
}
]
}
]
}
]
}
应用拉起
管理线程函数体持续从自己队列里面取消息,获取到消息之后调用对应的工作线程进行process工作,也就是说队列是属于管理线程的,工作线程从管理线程取消息,往管理线程发消息
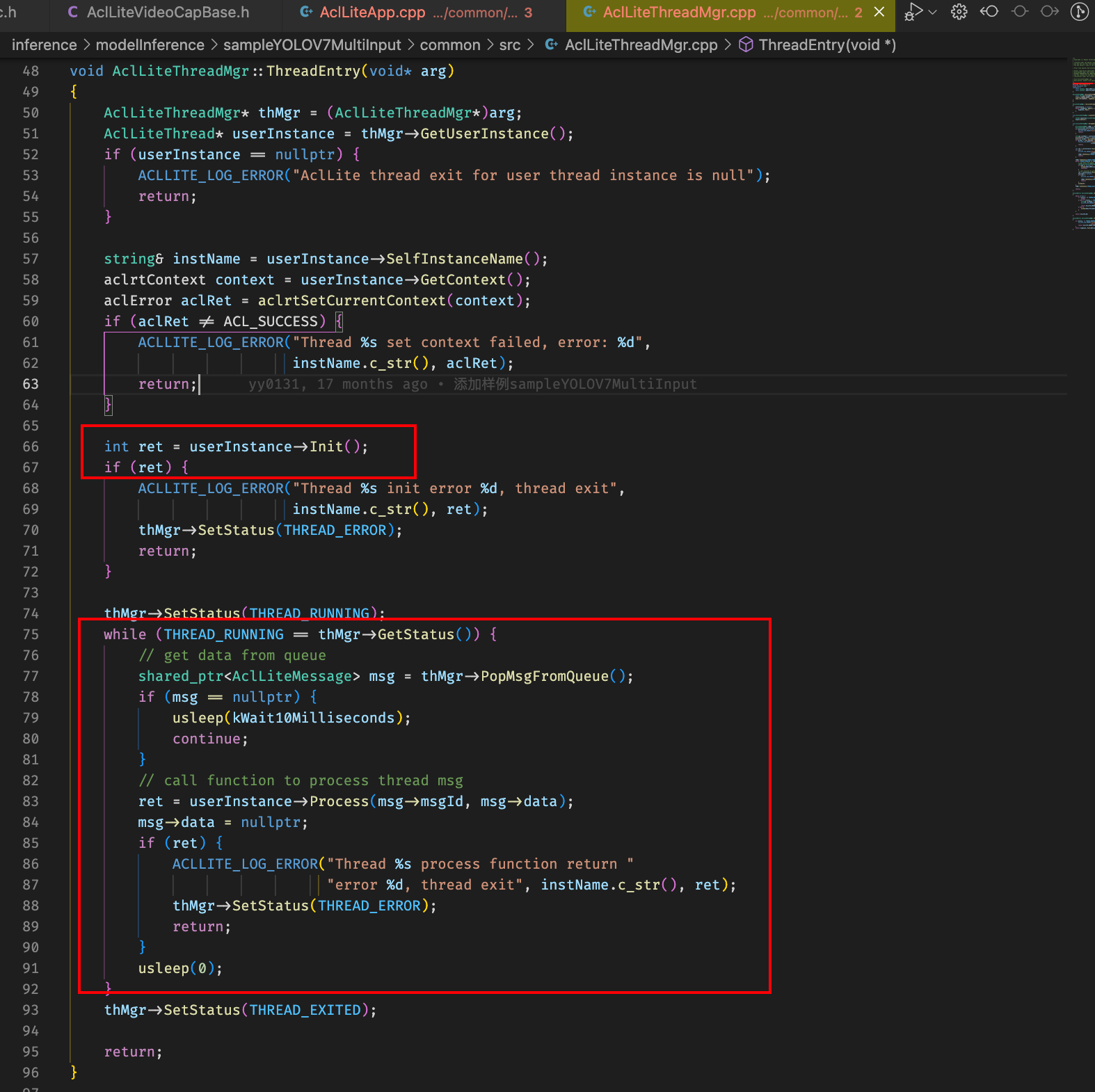
为啥线程能持续轮转直至输入被推理结束就在于datainput线程会判断当前帧是不是最后一帧,如果不是的话它会一直往自己的管理线程抛MSG_READ_FRAME message让一整套流水线不会停止
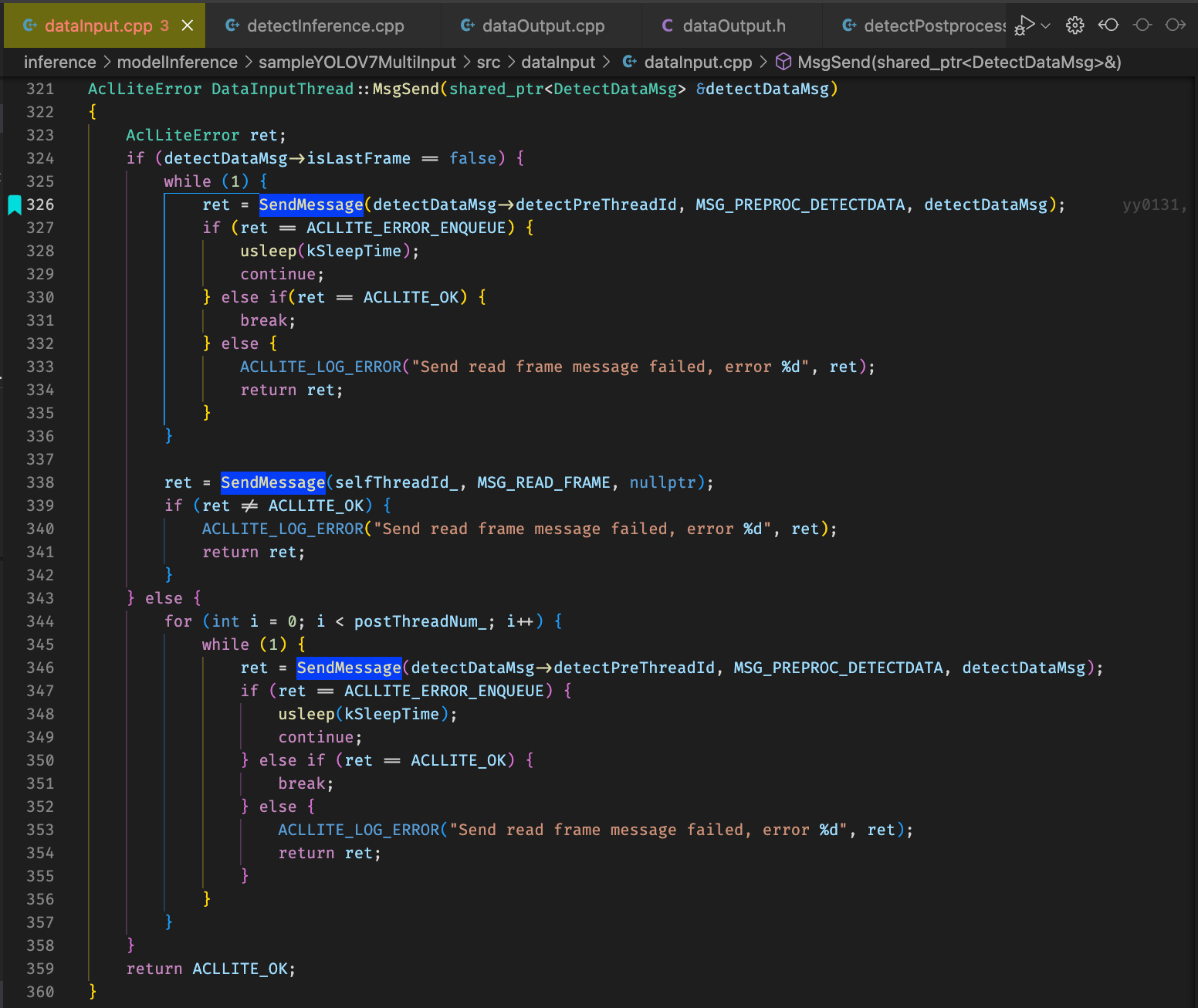
推理线程为配置文件中model_config的长度,一般一个om文件一个推理线程,数据输入、数据预处理、数据输出线程为model_config.io_info长度,即几路视频几组线程,数据后处理线程和数据数据输入线程则是model_config.postnum:1的关系
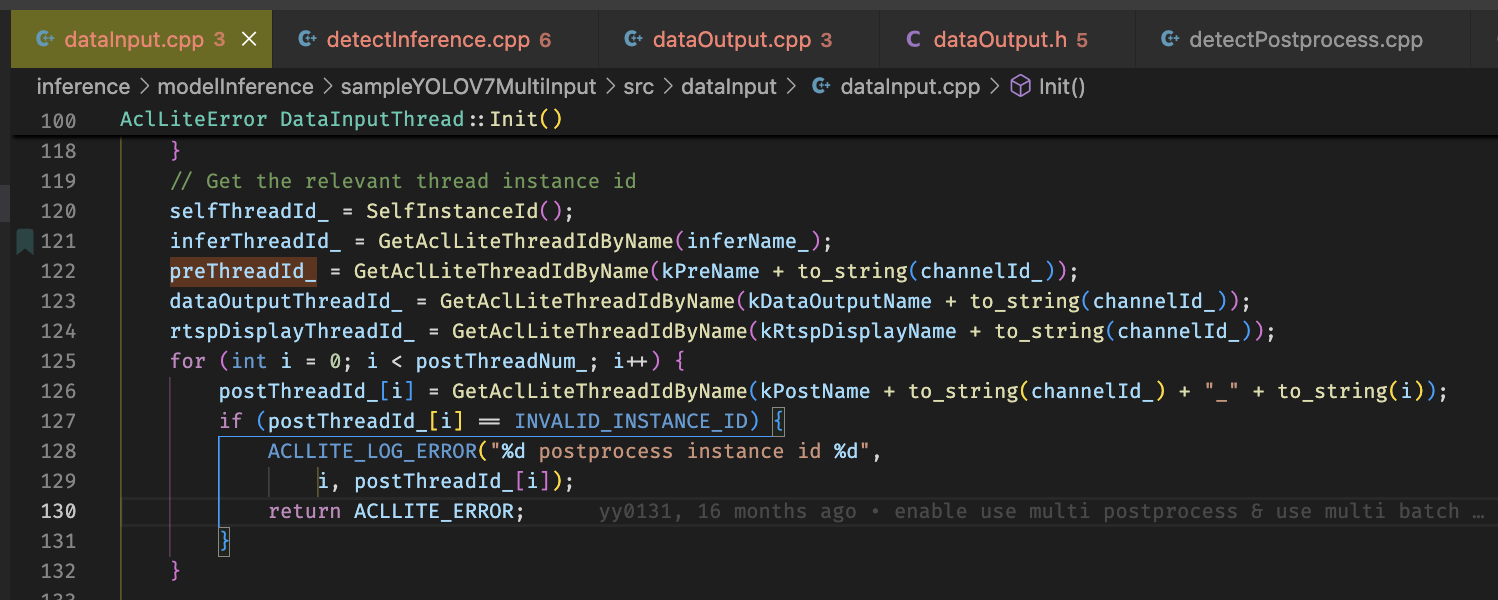
线程之间关系由表示线程类别和channelId组合的字符串进行串联起来
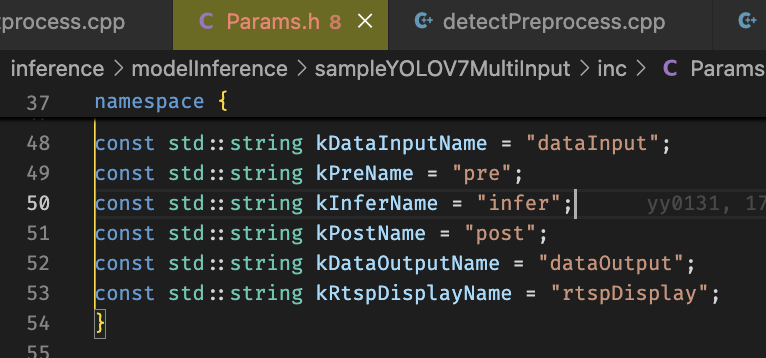
配置文件中的model_batch配置一次datainput线程读取的帧数
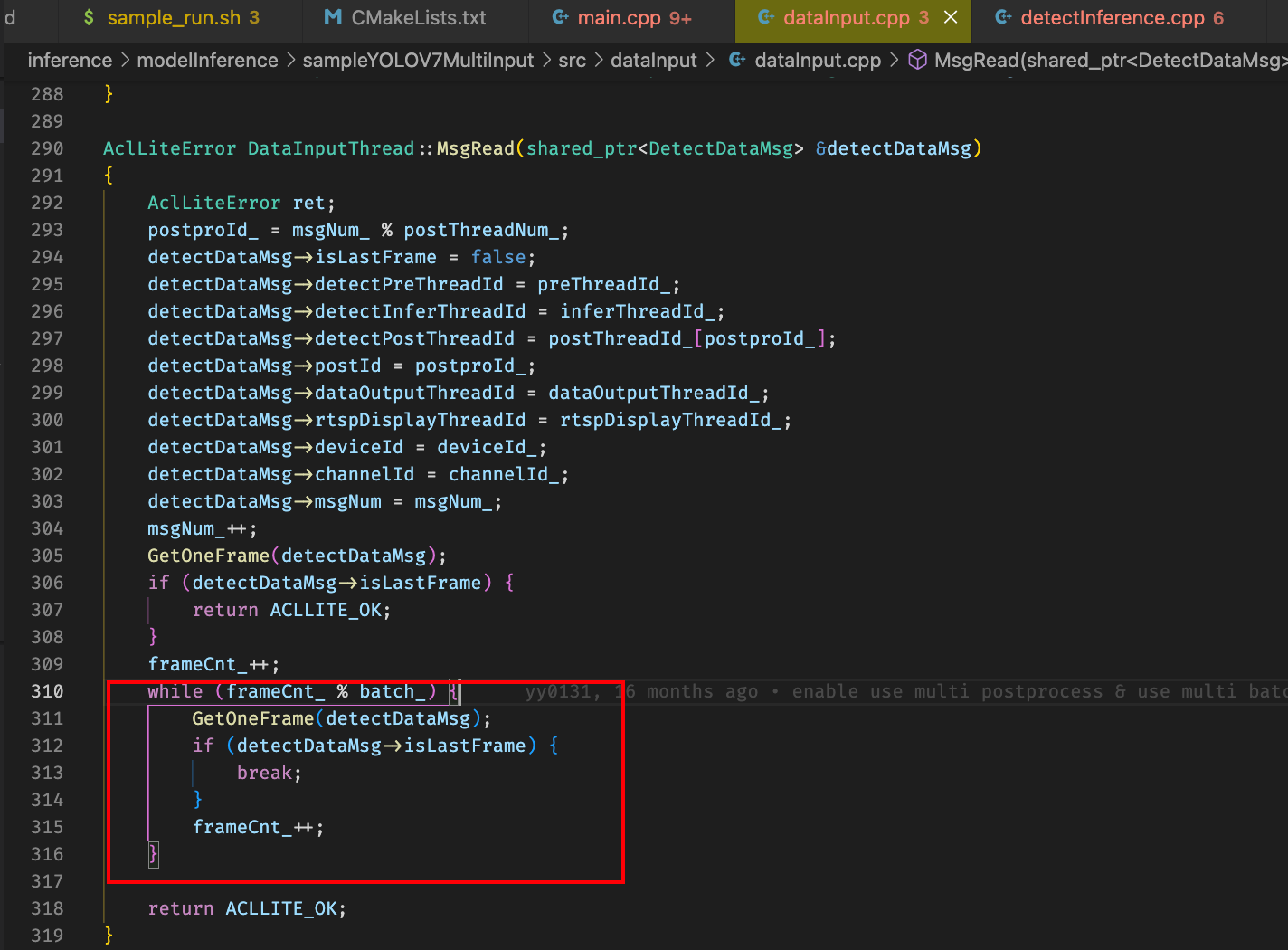
拼接示例代码:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 读取两张图片
cv::Mat img1 = cv::imread("image1.jpg");
cv::Mat img2 = cv::imread("image2.jpg");
// 检查图片是否成功加载
if (img1.empty() || img2.empty()) {
std::cout << "Could not open or find the images!" << std::endl;
return -1;
}
// 调整大小确保两张图片的高度或宽度一致(根据拼接方式)
if (img1.size() != img2.size()) {
cv::resize(img2, img2, img1.size());
}
// 水平拼接
cv::Mat h_concat;
cv::hconcat(img1, img2, h_concat);
// 垂直拼接
cv::Mat v_concat;
cv::vconcat(img1, img2, v_concat);
// 显示拼接后的图片
cv::imshow("Horizontal Concatenation", h_concat);
cv::imshow("Vertical Concatenation", v_concat);
// 保存拼接后的图片
cv::imwrite("h_concat.jpg", h_concat);
cv::imwrite("v_concat.jpg", v_concat);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
编码调试记录
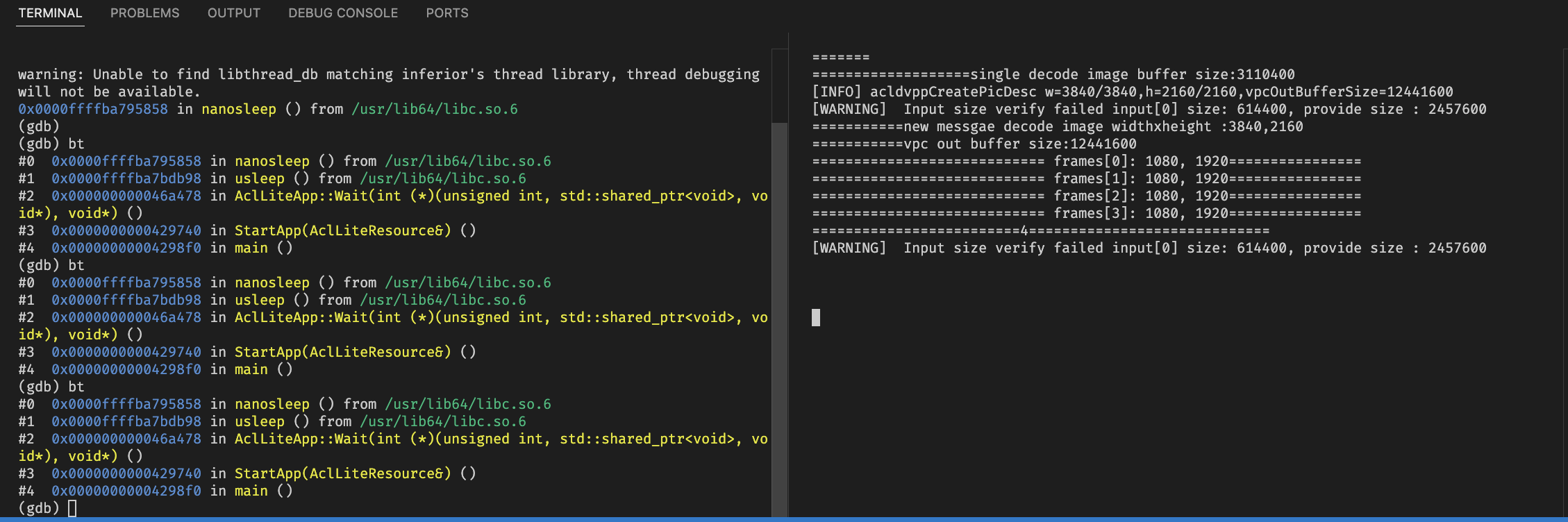
异常没有frame
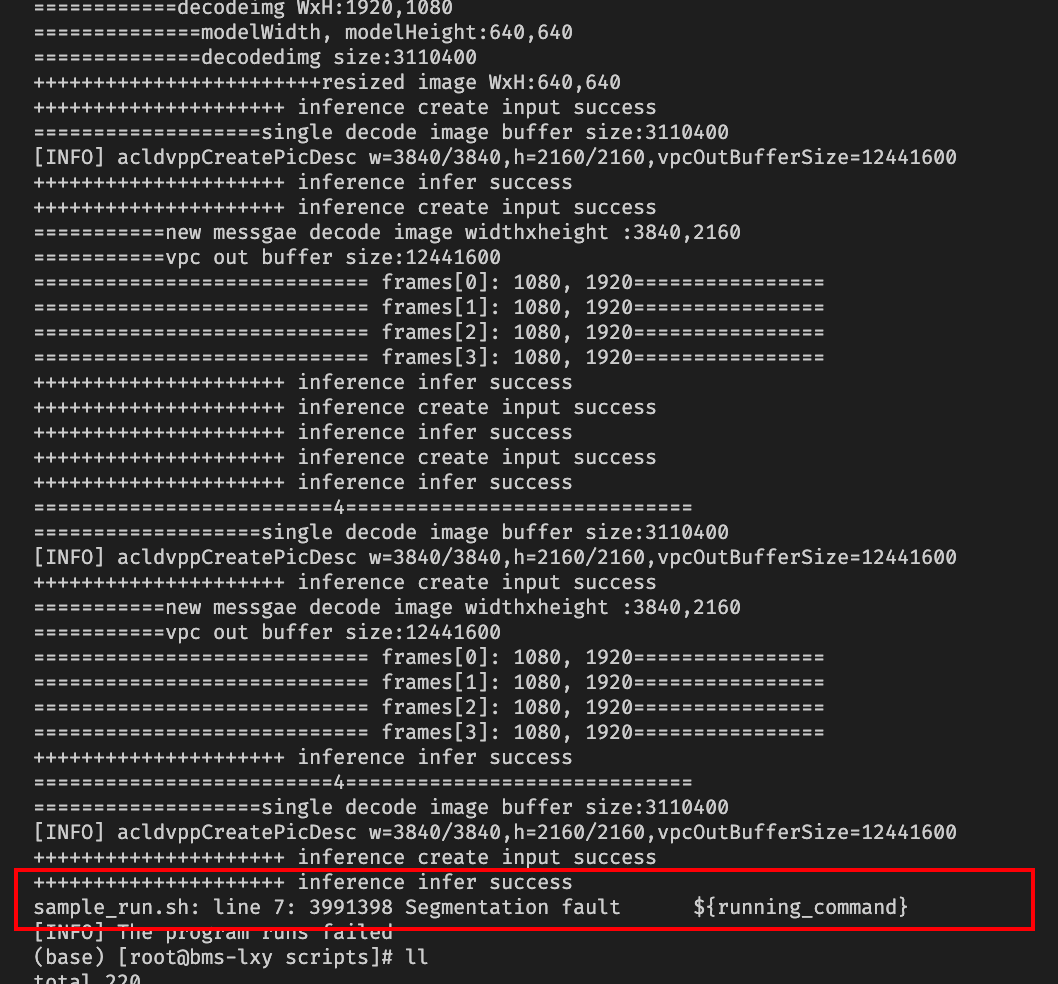
ulimit -c unlimited
echo "core-%e-%p-%t" > /proc/sys/kernel/core_pattern
加上debug编译选项,这里直接将vpc拼接之后的buffer直接赋值到messsgae里面的decodeimage.data
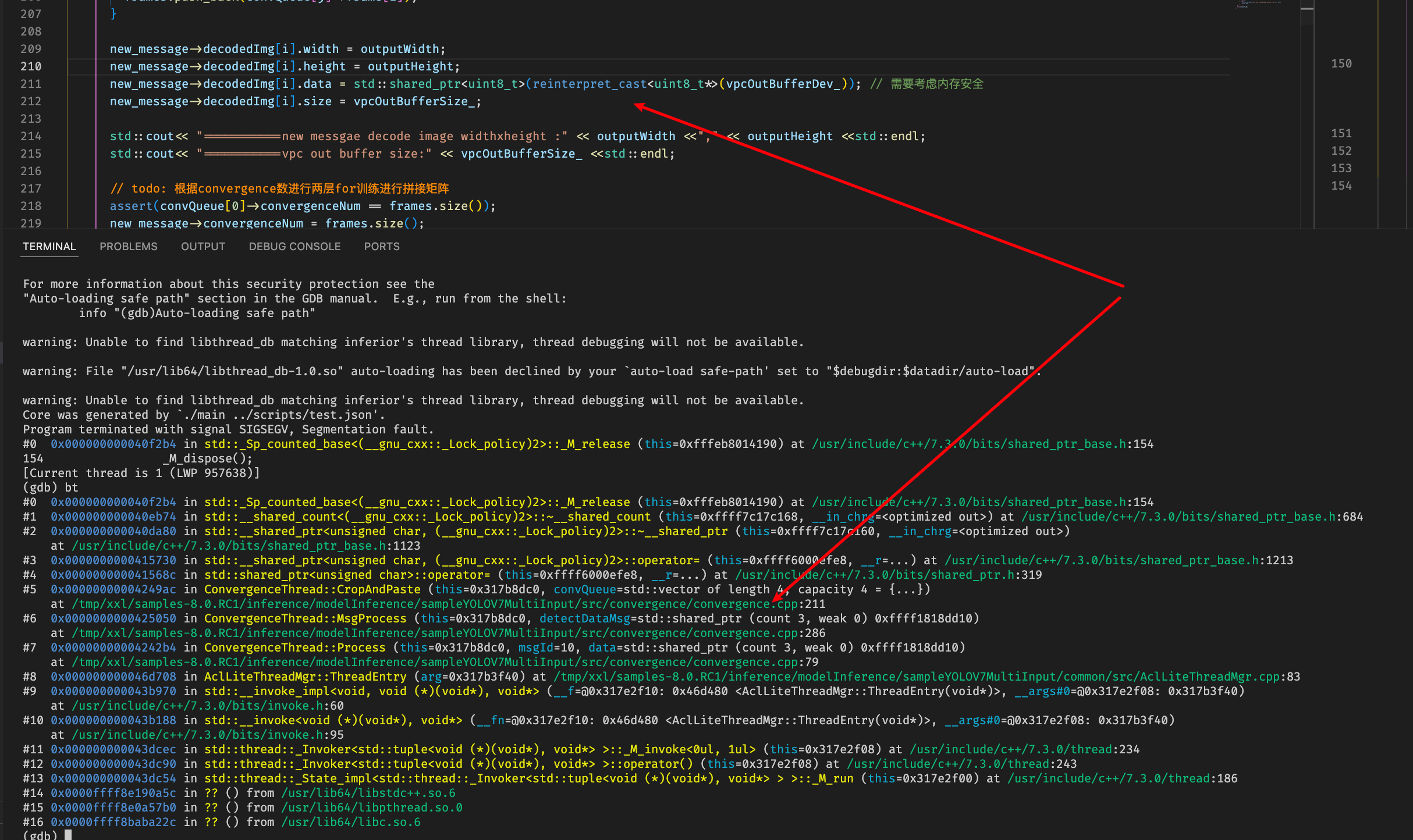
首先decode image先make shared之后再进行将vpc buffer拷贝一下,但是内存地址无法获取,怀疑是设备侧buffer需要按照特定接口进行拷贝
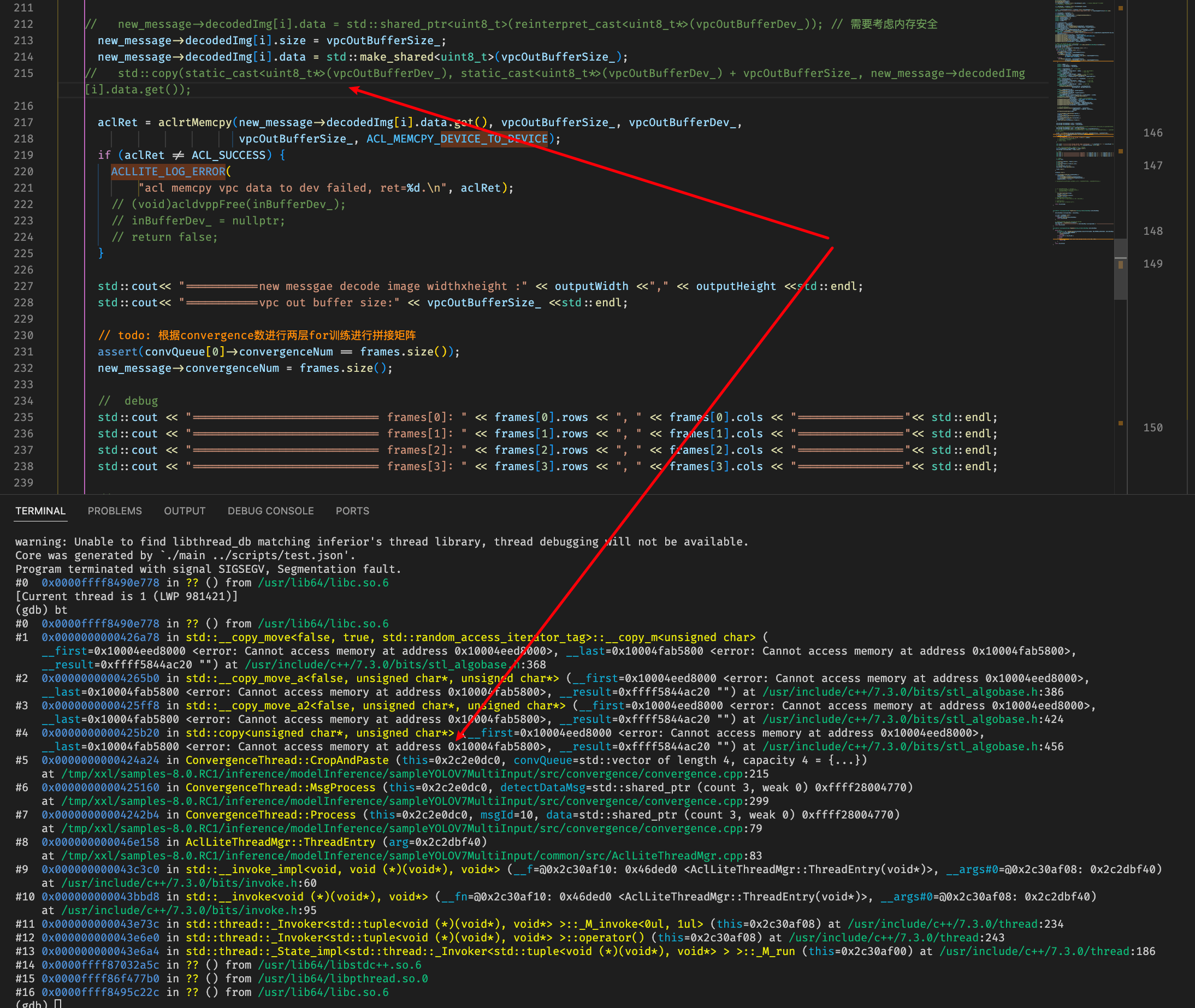
换成对应的接口进行拷贝
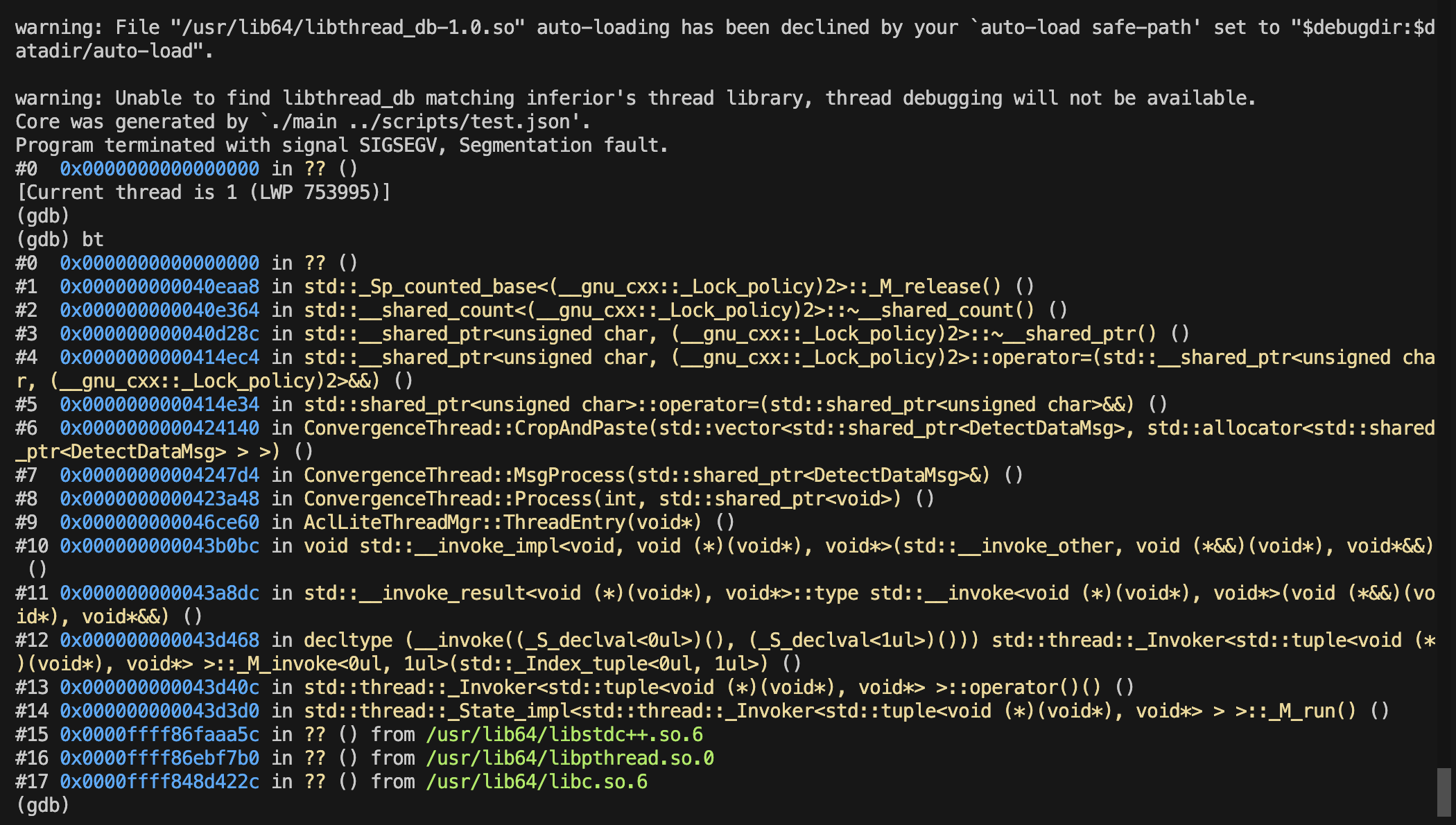
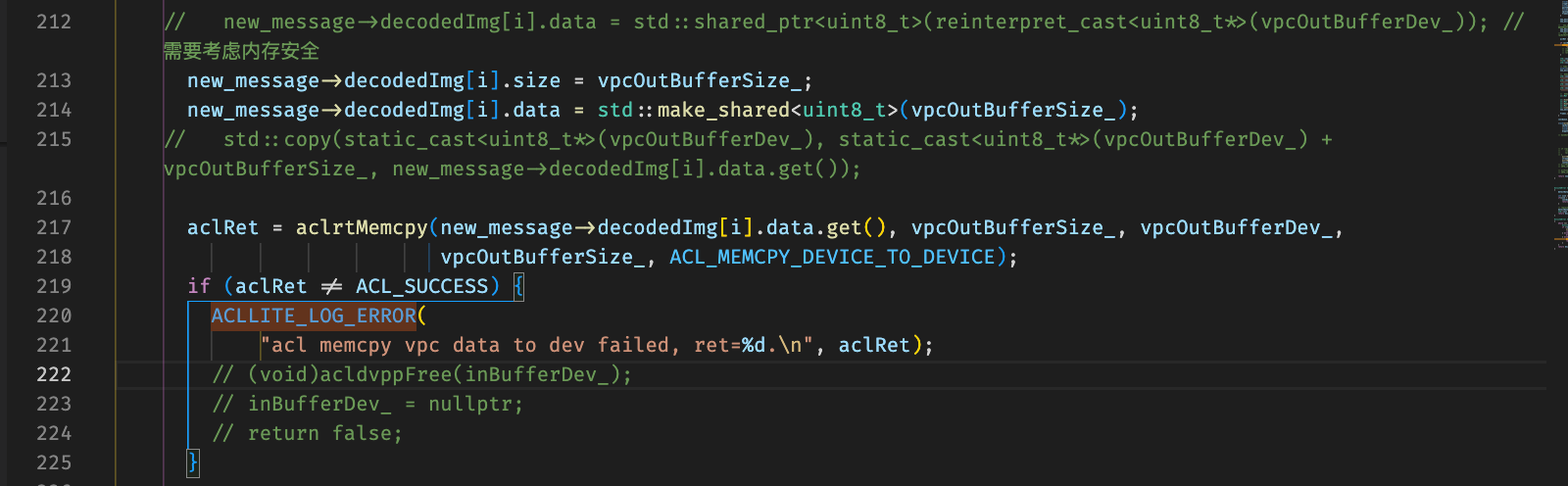 之后出现shared ptr析构函数出现segament fault:
之后出现shared ptr析构函数出现segament fault:
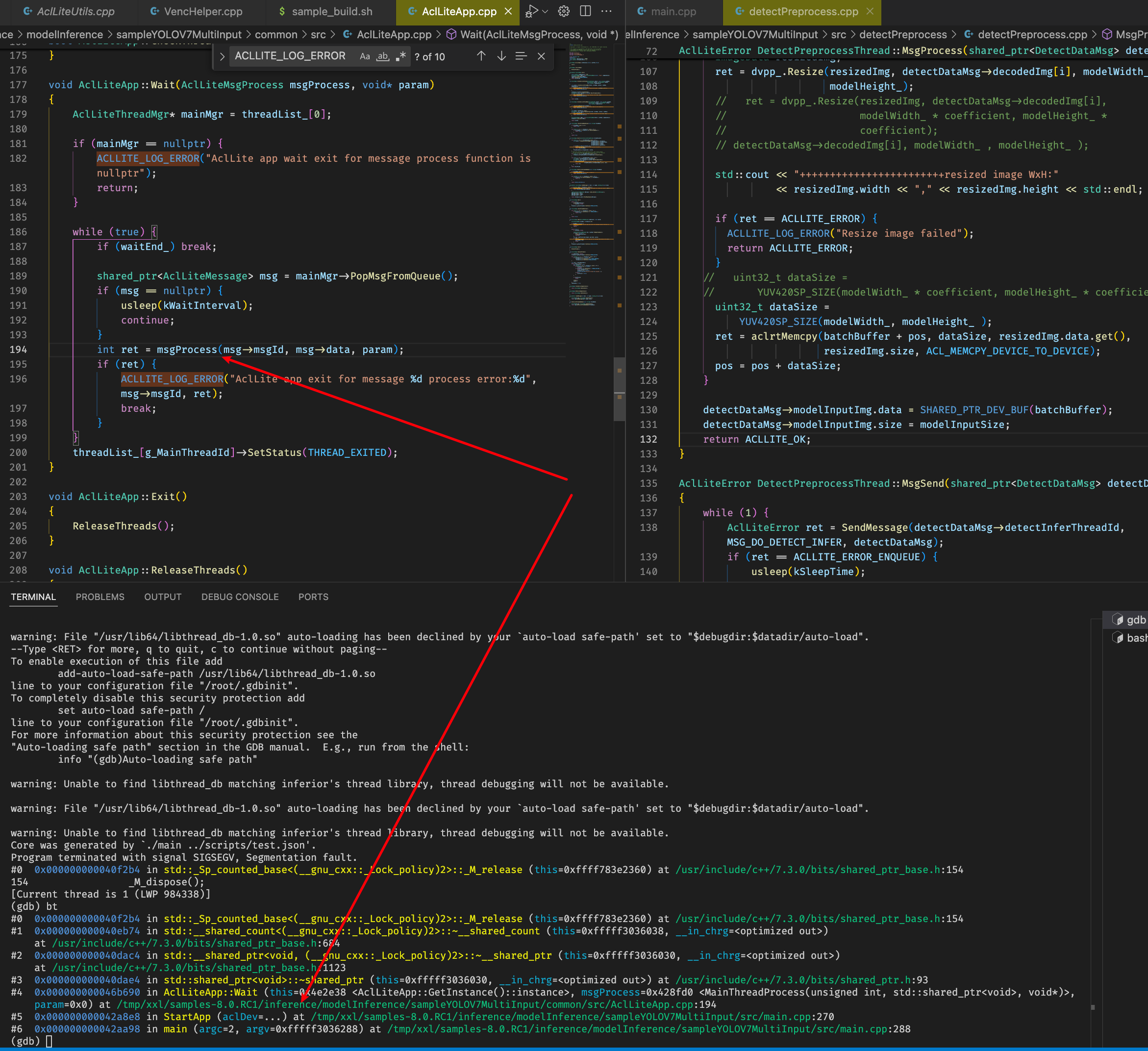
分析运行日志,在segement fault退出之前还有以下错误:
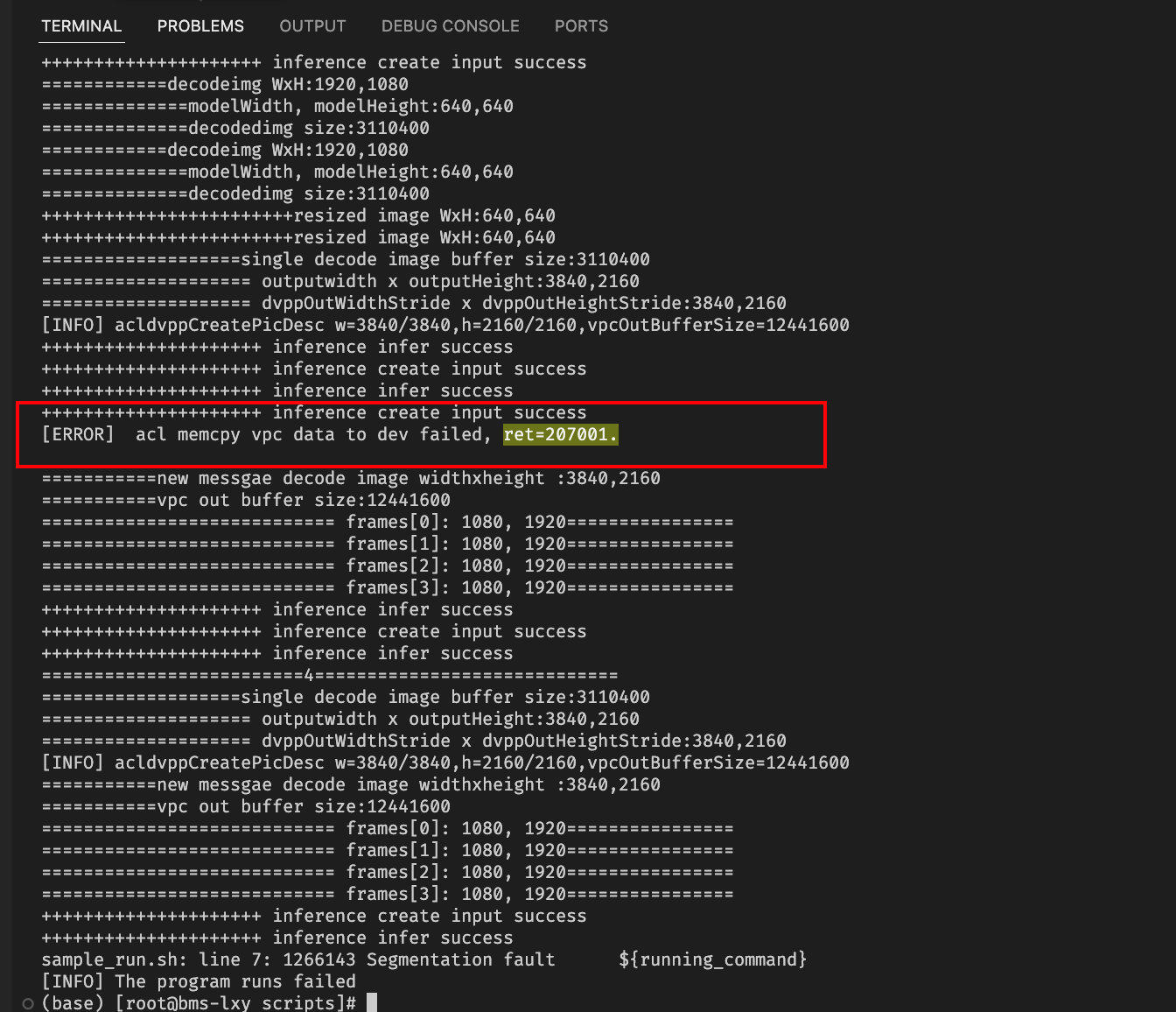
查看昇腾错误码说明: https://www.hiascend.com/document/detail/zh/canncommercial/80RC22/apiref/appdevgapi/aclpythondevg_01_0911.html
对应解释为内存申请失败
咨询分析怀疑点还是decoded image 的buffer相关定义和操作存在问题,追踪原始decoded image buffer的来源,其中可以看到先是从acldvppPicDesc类型的指针通过acldvppGetPicDescData接口获取对应的buffer,然后通过宏来将void*类型的buffer转为shared_ptr<uint_8>类型并且指定acldvppFree为资源释放函数
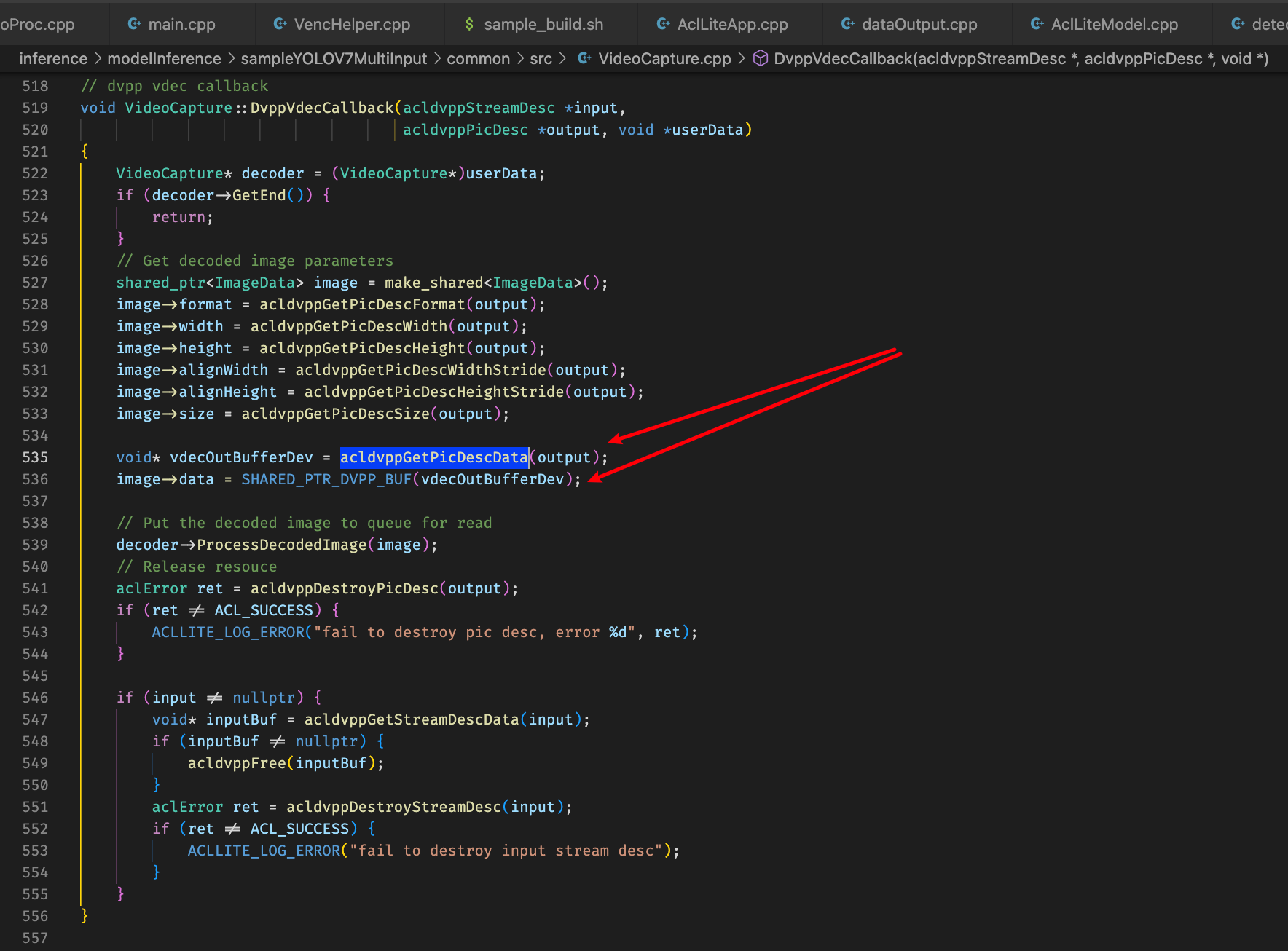

按照此类规范进行修改从vpc接口输出获取buffer到decode image中
之后出现赋值的data赋值的时候segmentation fault错误,
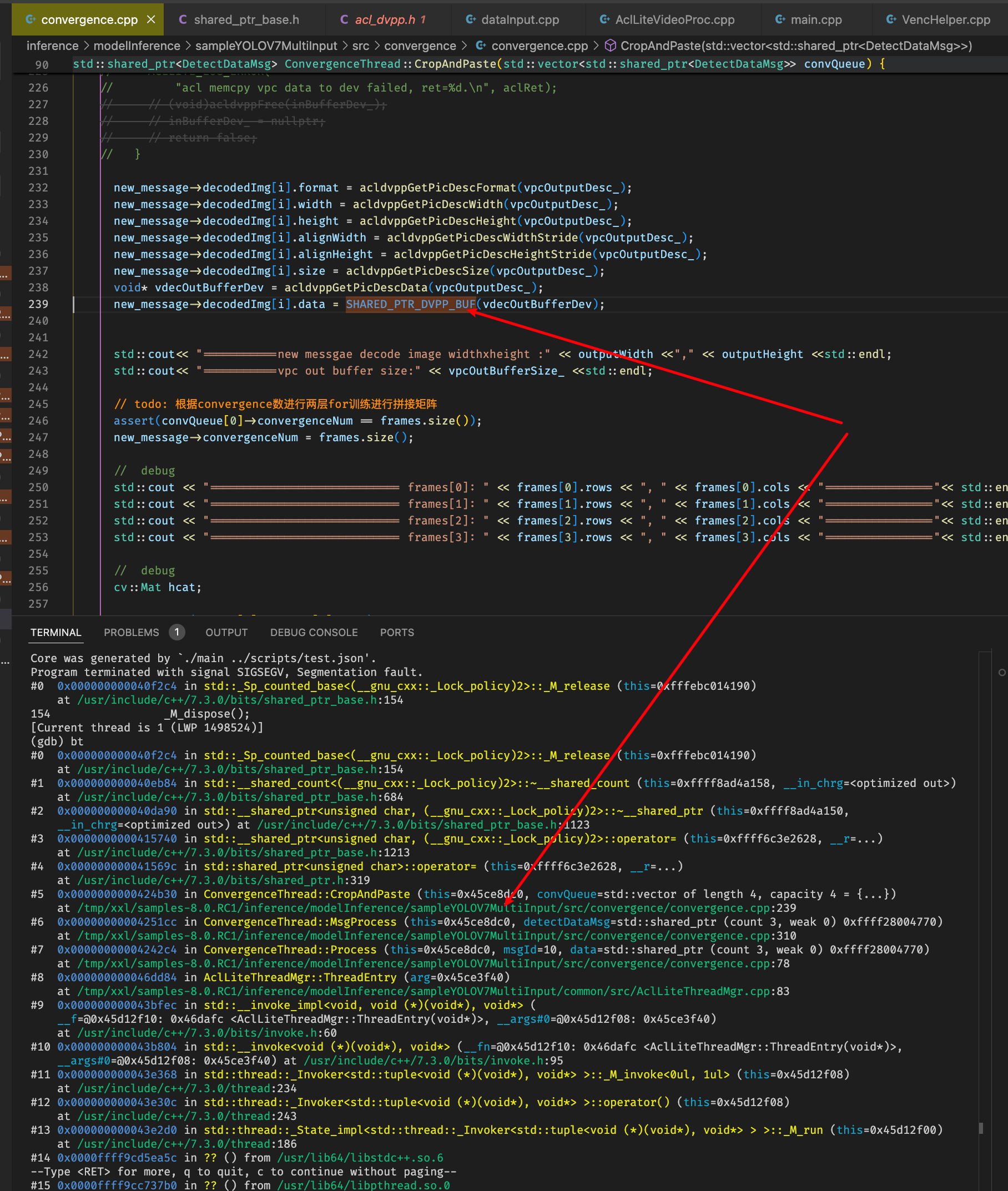
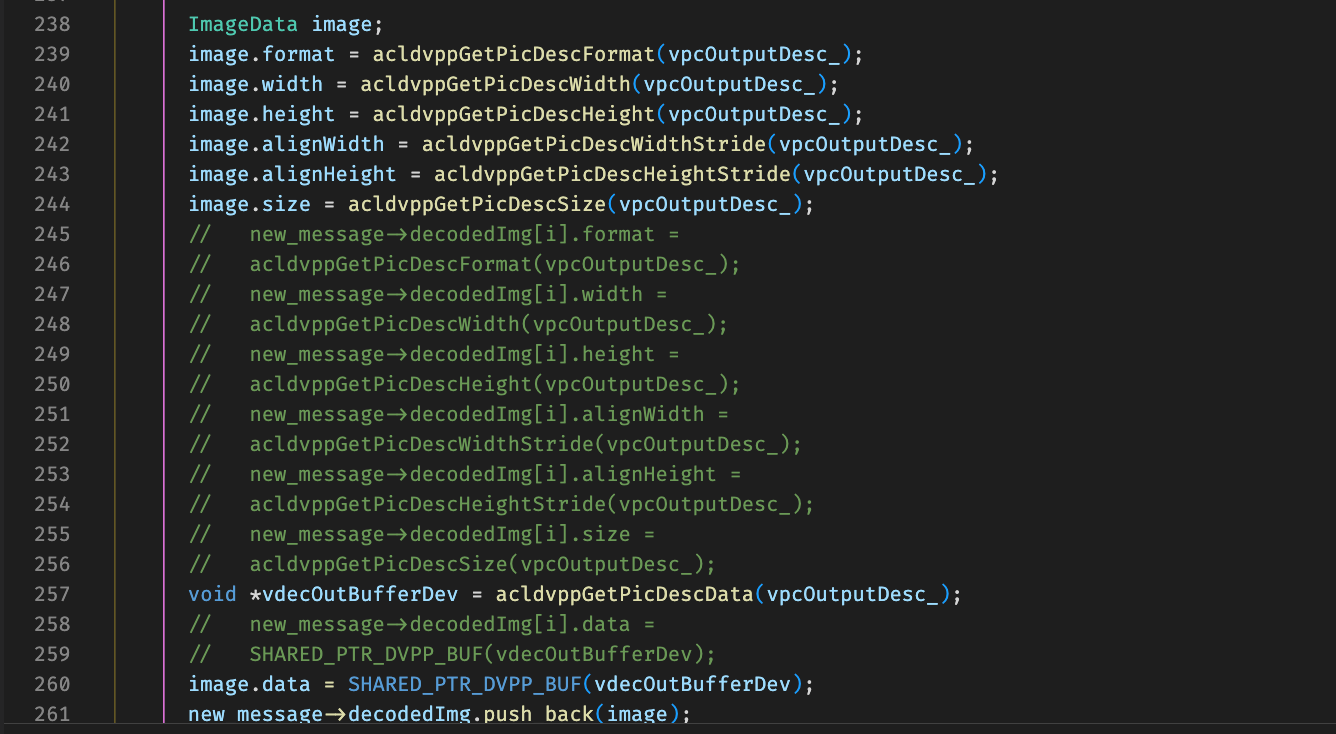
排查发现new_message的decodedImg循环取帧前已经clear的,需要重新组装之后再append才行,改为如下:
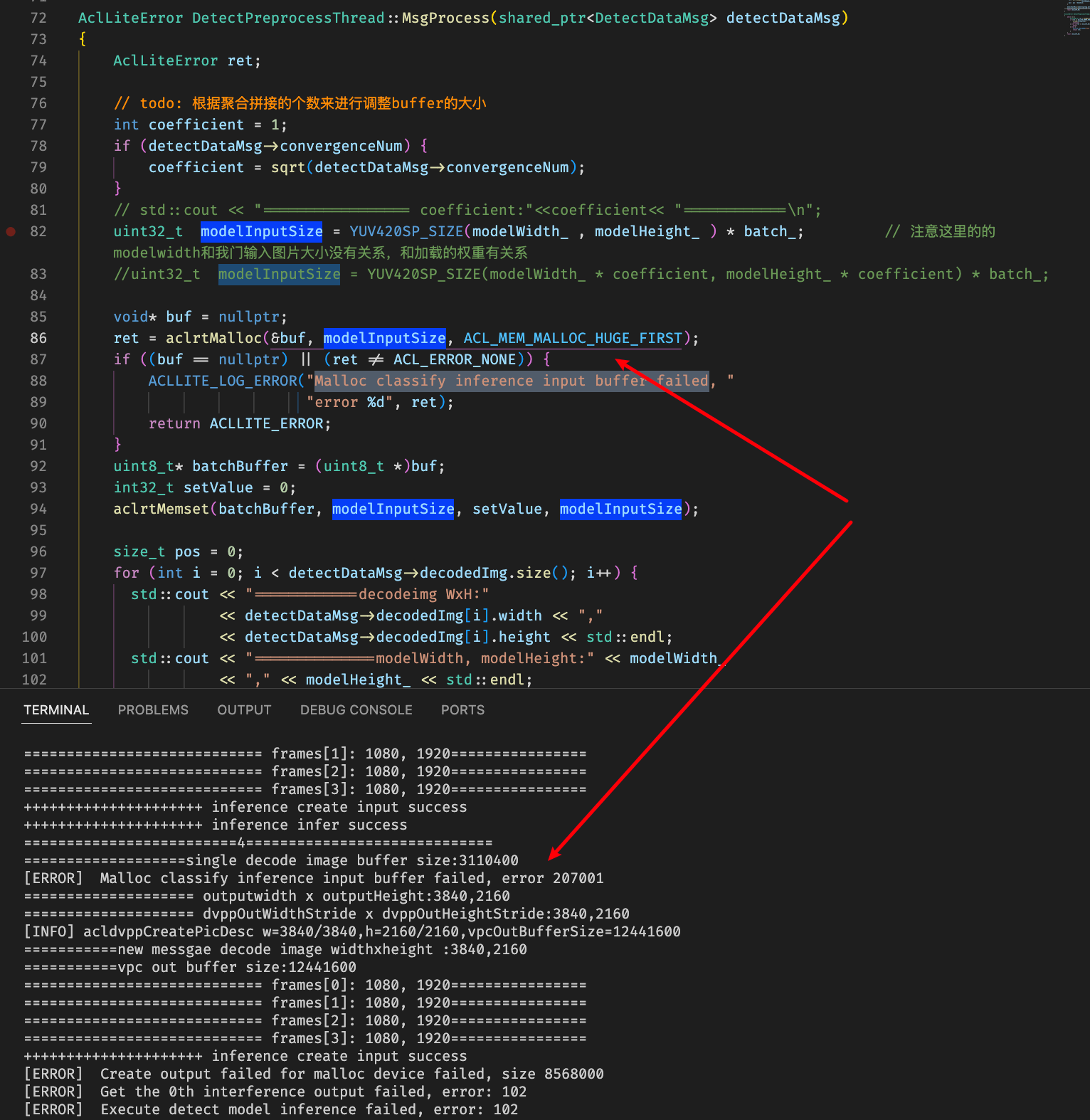
重新编译推理出现malloc显存错误:
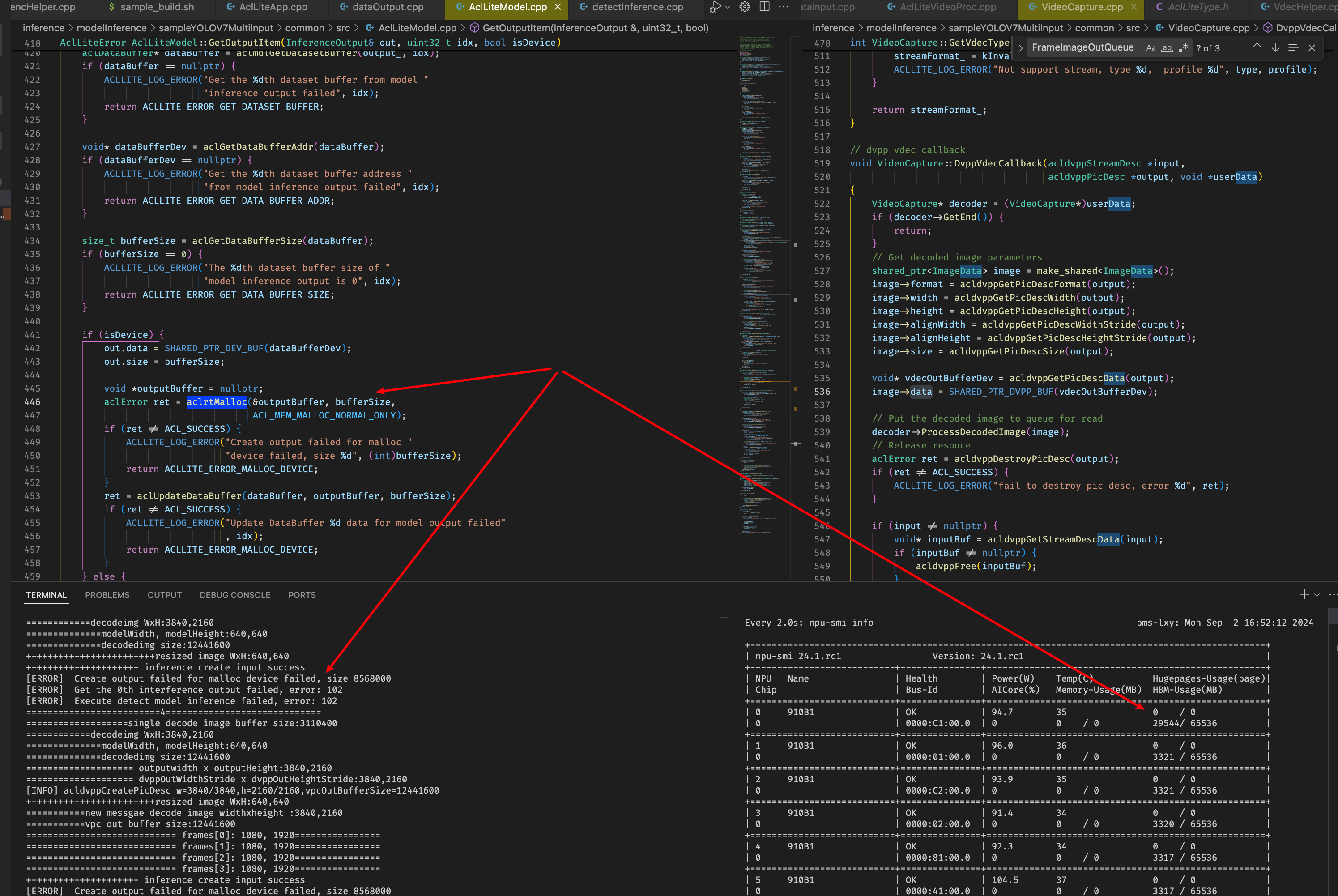
查看到相关错误:https://www.hiascend.com/forum/thread-0218114317059345009-1-1.html
了解到单进程device侧有16G约束,超过16G可能会错误,这里怀疑是进程中存在一些内存没有进行释放导致累计
排查是输出线程没有consume推理结果,导致显存没法释放
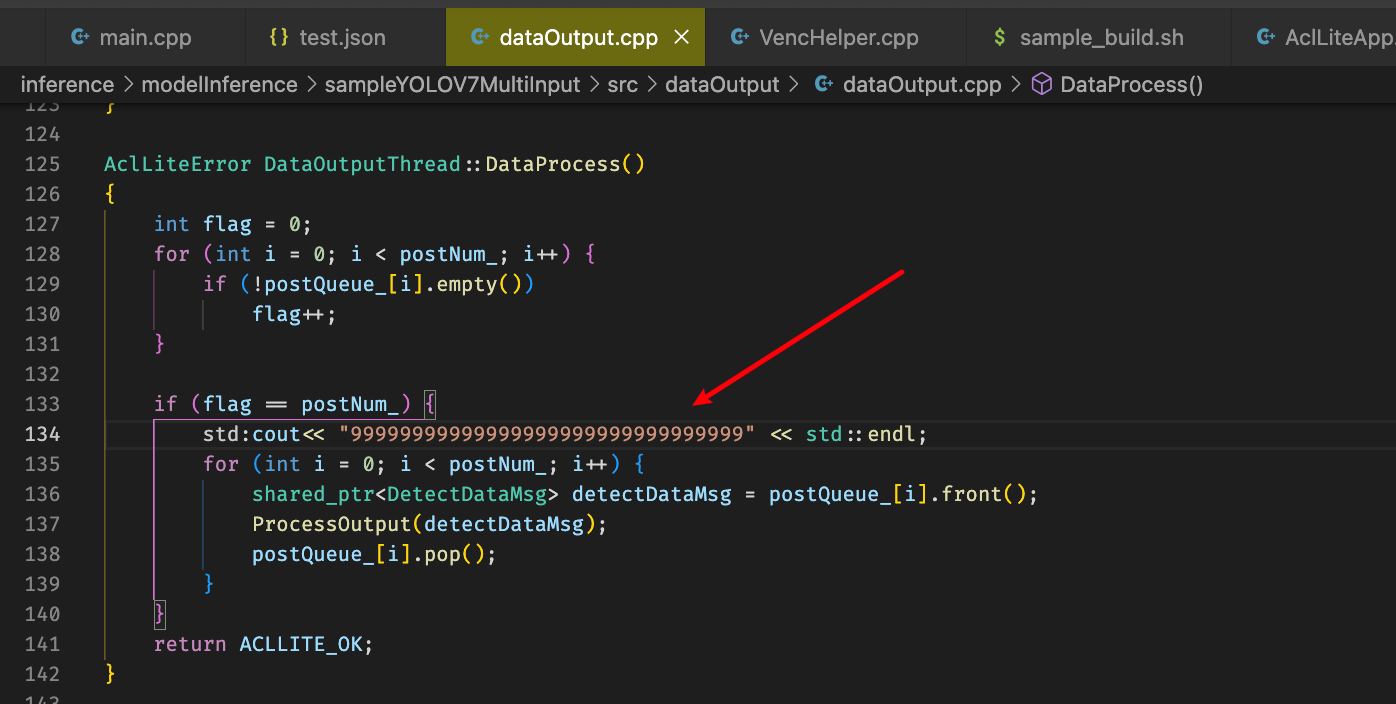
将postnum改为1,可以输出图片,
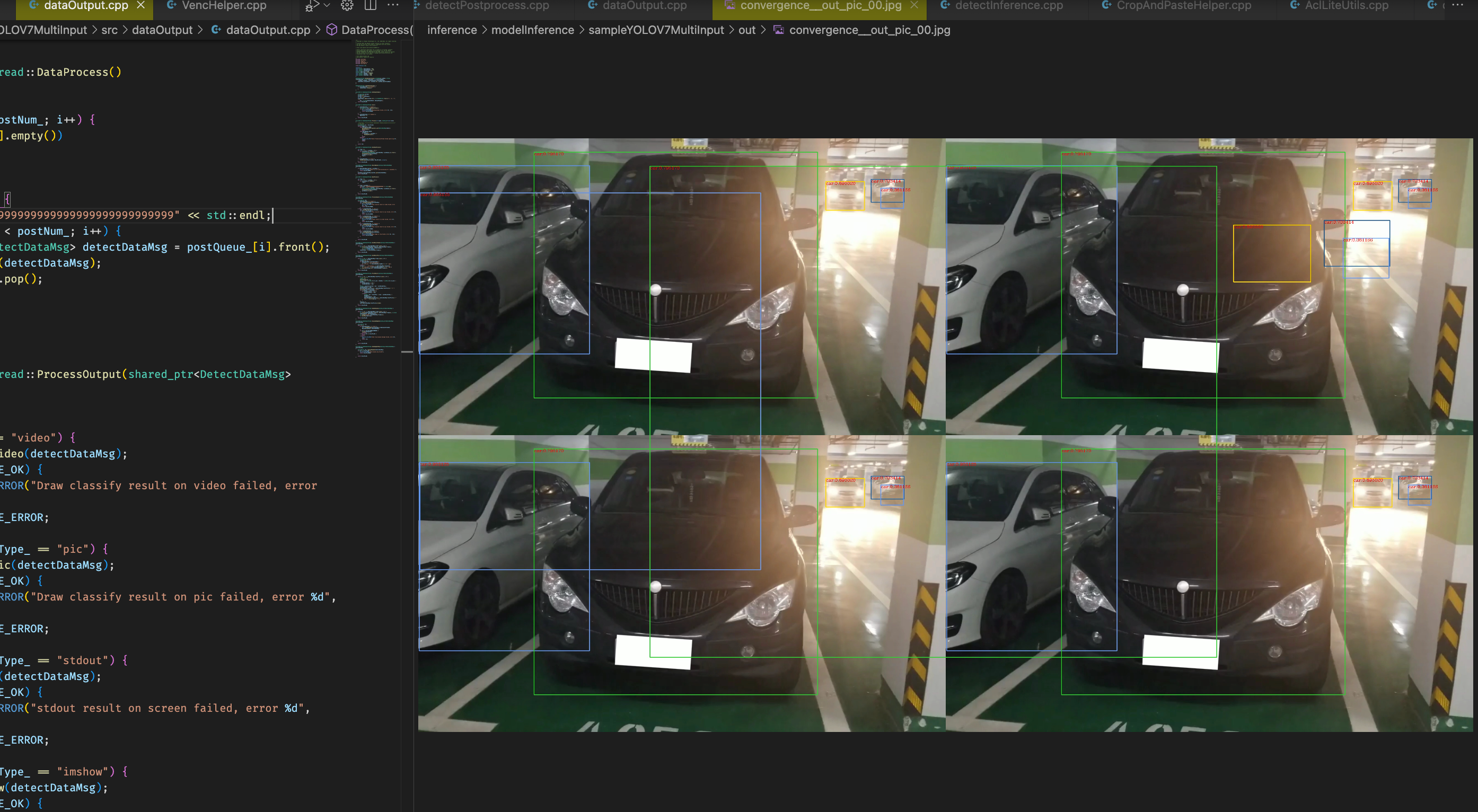
但是存在一个问题,只有一张图片,感觉可能是message的msgnum没有递增导致的
定位到这里进行croppaste操作的时候这里传入收集视频帧message的不是传引用而是传值,导致后面一直处理的都是最开始的四帧,改为传引用之后可以生成多张图片,但是存在有些图片没有拼接,拼接的图片只有部分区域有识别结果,目前初步解决方案为拼接的时候得保序,也就是得保证四张图片都是来自不同路的视频,且为相同时间帧
考虑到CropAndPaste函数传入的起始也是线程的内部属性,直接将函数改为签名为不需要传参类型
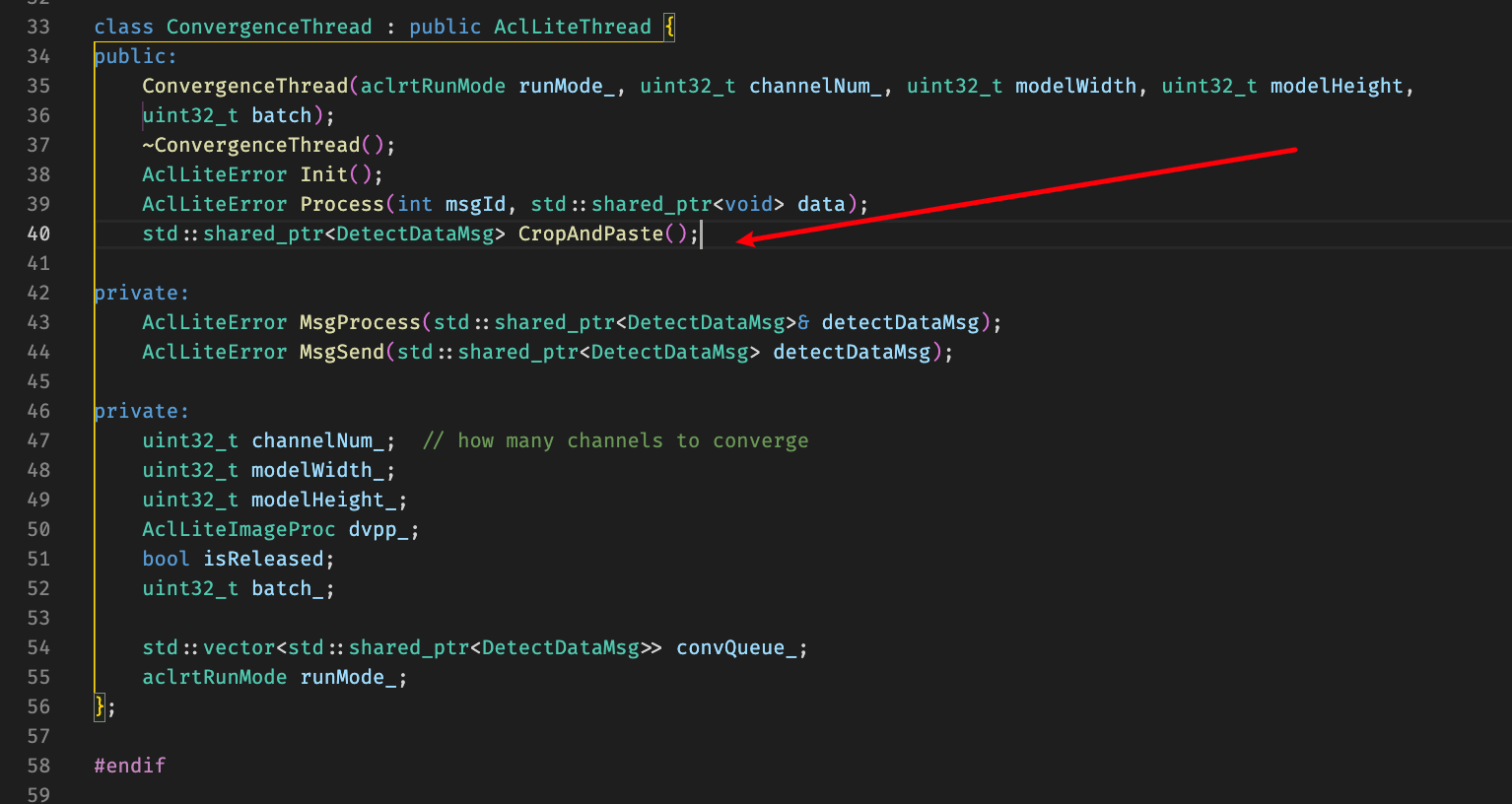
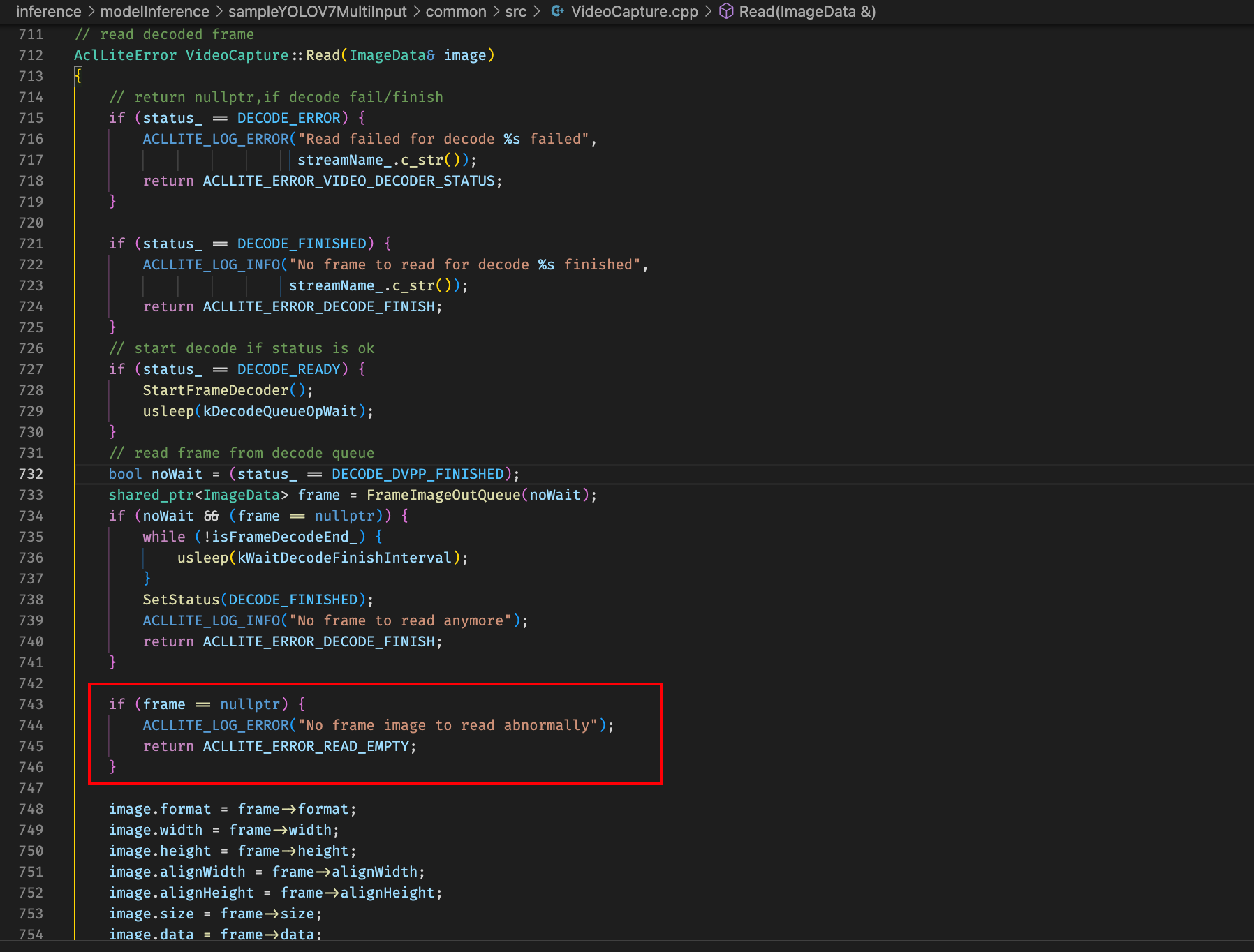
改完相关代码之后加上保序操作,去除保序操作发现程序会segmentation fault,调试发现从convQueue_取帧的时候最后一个message的decodeImg是空的?
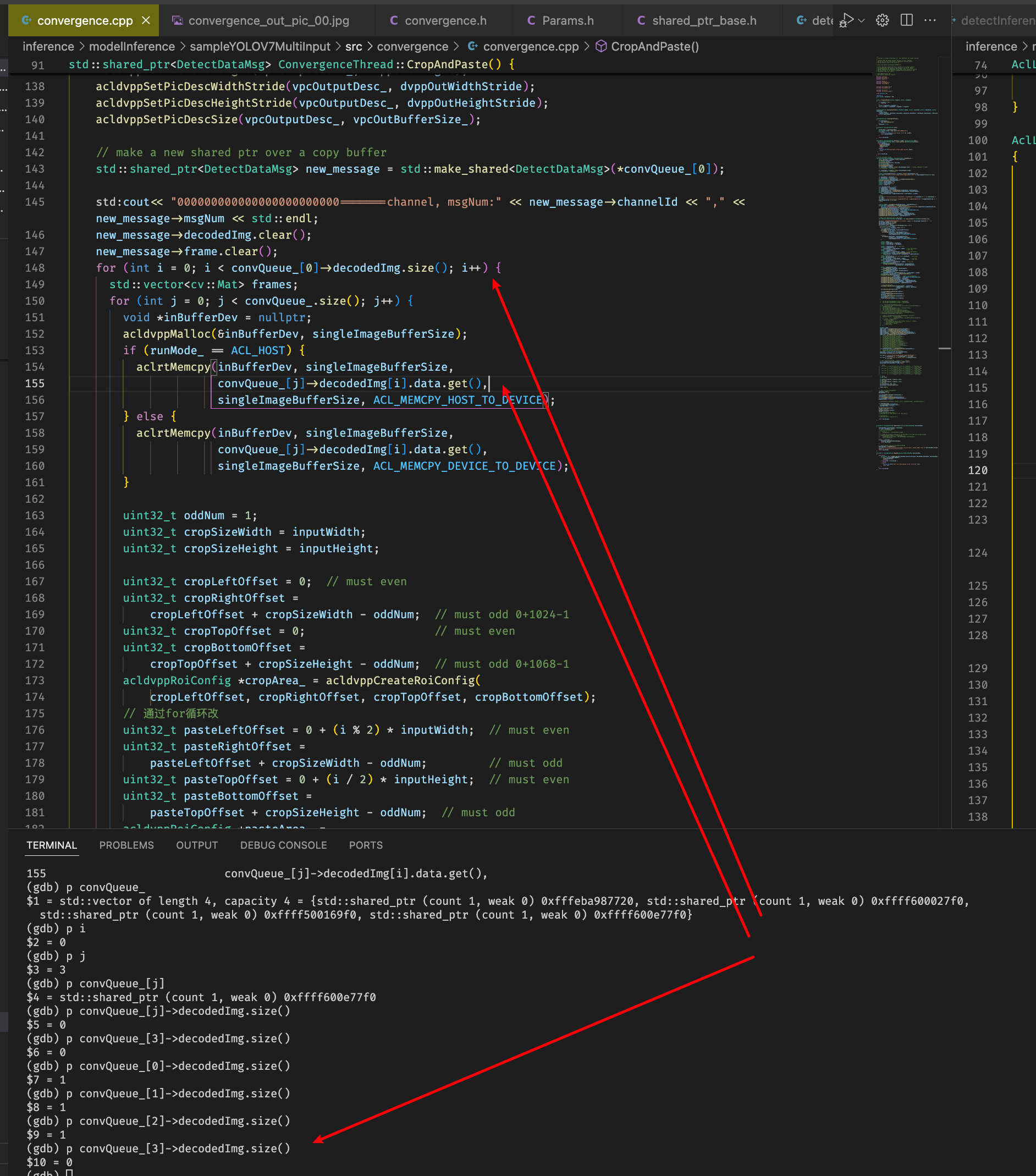
排查发现datainput进程getoneframe可能存在没有读取帧成功的情况,且没有对getonframe函数返回进行校验,增加校验
修改完只出图一个的bug之后发现出的多张图片很多都是四个区域只有左上角有推理框图结果,且有些图片并没有拼接,将代码改为固定四图进行推理发现正常,怀疑推理次数时间和次数有关?推理同一组图结果更全面?
先进行保序操作,convergence线程根据拿到消息的msgnum编码来看是不是属于同一批,也就是时间对的上的,对的上的存入预处理队列,待队列满取出进行拼接封装之后往下传递,否则通过管理线程抛给自己后续处理
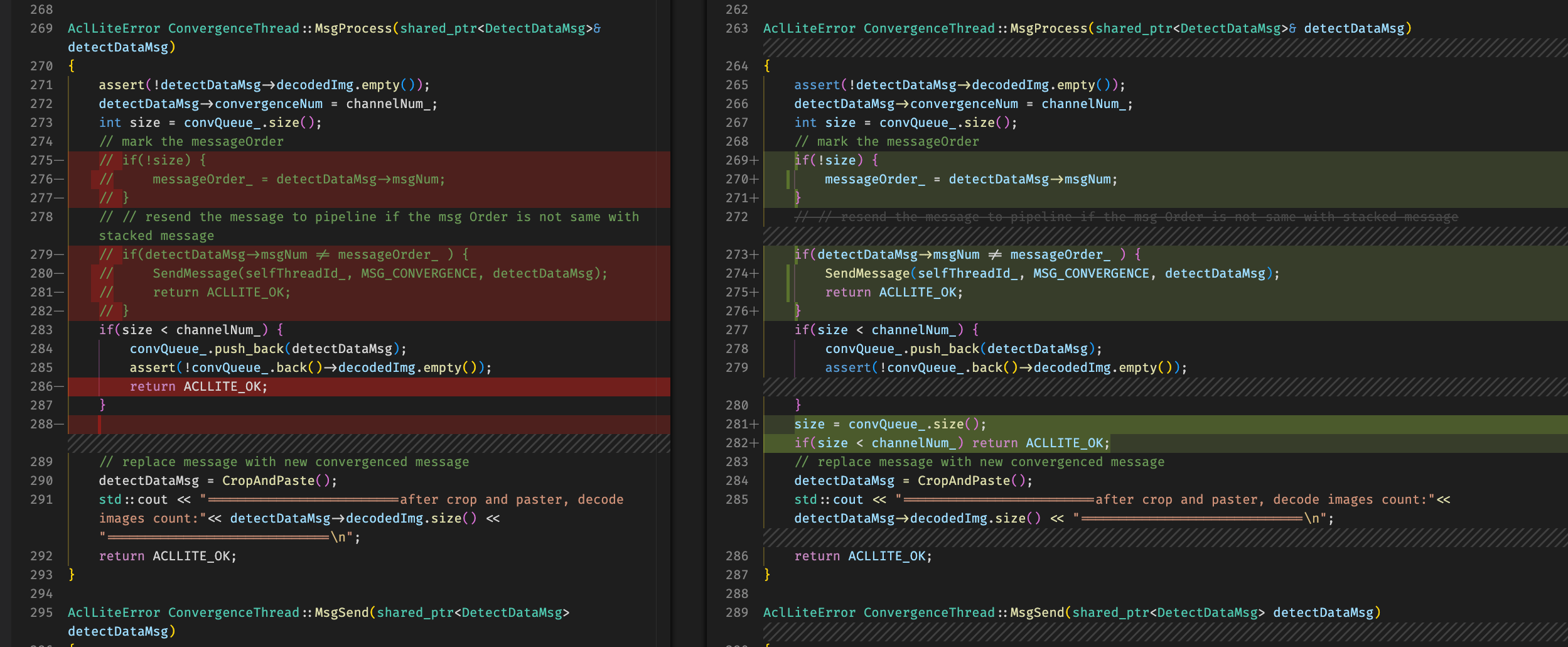
这样调试发现会存在内存申请失败,怀疑是不是同一个批次的往外抛下次处理的这种效率比较低(必须按照msgnum顺序处理)
改成全部按msgnum入队,每次查询看一下是否满了,满了直接处理(不需要按照msgnum顺序处理,有资源就直接处理)