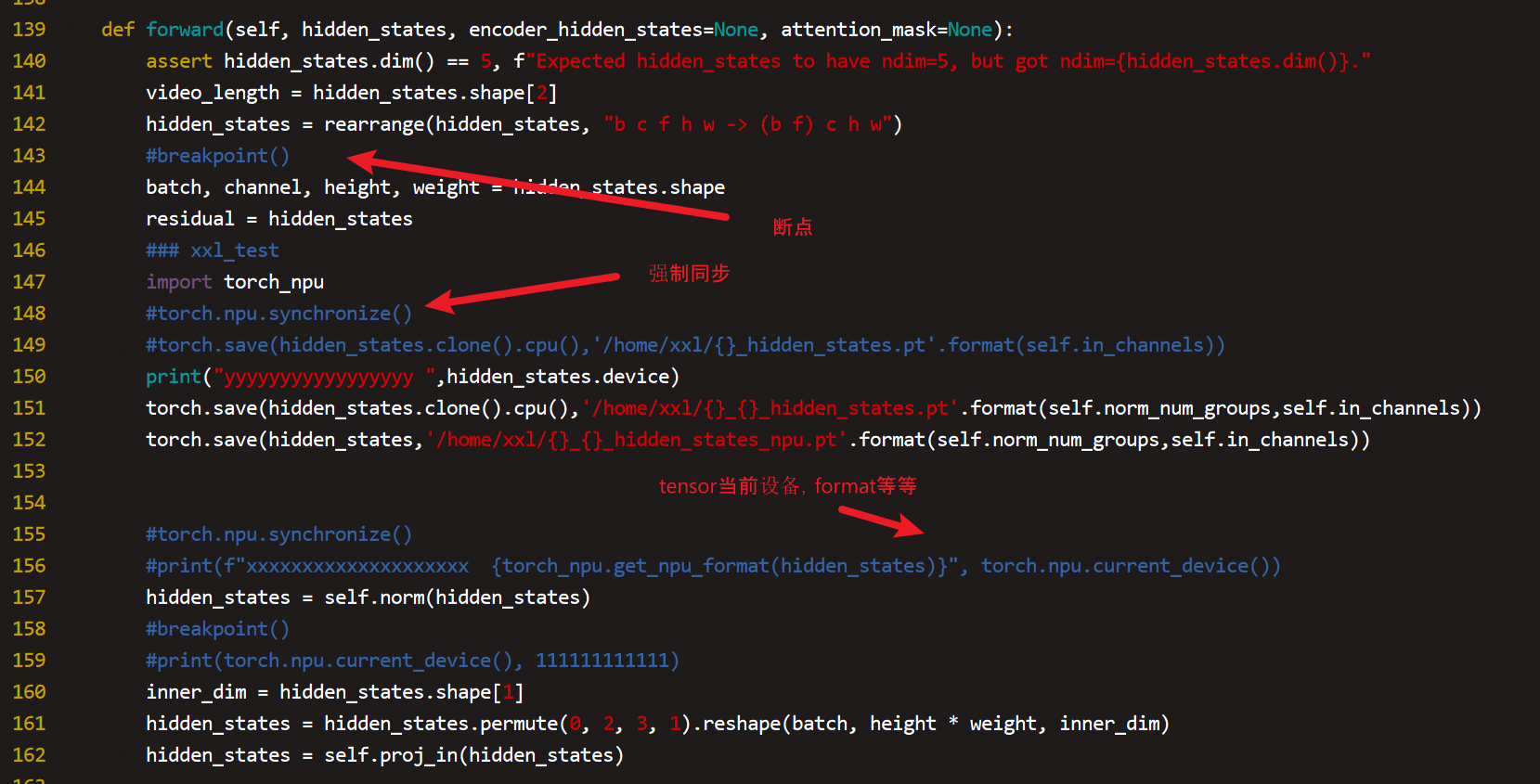
360反向报错定位笔记
背景:
360客户在昇腾机器测试AnimateDiff模型,遇到一个必现的一个反向报错
定位思路:找出错误算子,构造单算子用例验证
由于问题在单卡上也能必现,我们在训练跑测的时候可以只用单卡进行测试,将日志按时间分开,
注意要看到调用栈需要使用环境变量export ASCEND_LAUNCH_BLOCKING=1
训练脚本:
#!/bin/bash
pkill -9 python
#source /usr/local/Ascend/ascend-toolkit/set_env.sh
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/driver
export ASCEND_PROCESS_LOG_PATH=/home/xxl/`date +%m%d`/`date +%H%M`/
if [ ! -d $ASCEND_PROCESS_LOG_PATH ];then
mkdir -p $ASCEND_PROCESS_LOG_PATH
fi
export ASCEND_LAUNCH_BLOCKING=1
#NPU_VISIBLE_DEVICES=0 nohup torchrun --nnodes=1 --nproc_per_node=1 train.py --config configs/training/my_exps/mm_v1/training_video_bdm_mm_v1_exp2.yaml 2>&1 > $ASCEND_PROCESS_LOG_PATH/train.log &
torchrun --nnodes=1 --nproc_per_node=1 train.py --config configs/training/my_exps/mm_v1/training_video_bdm_mm_v1_exp2.yaml
#torchrun --nnodes=1 --nproc_per_node=8 train.py --config configs/training/my_exps/mm_v1/training_video_bdm_mm_v1_exp2.yaml
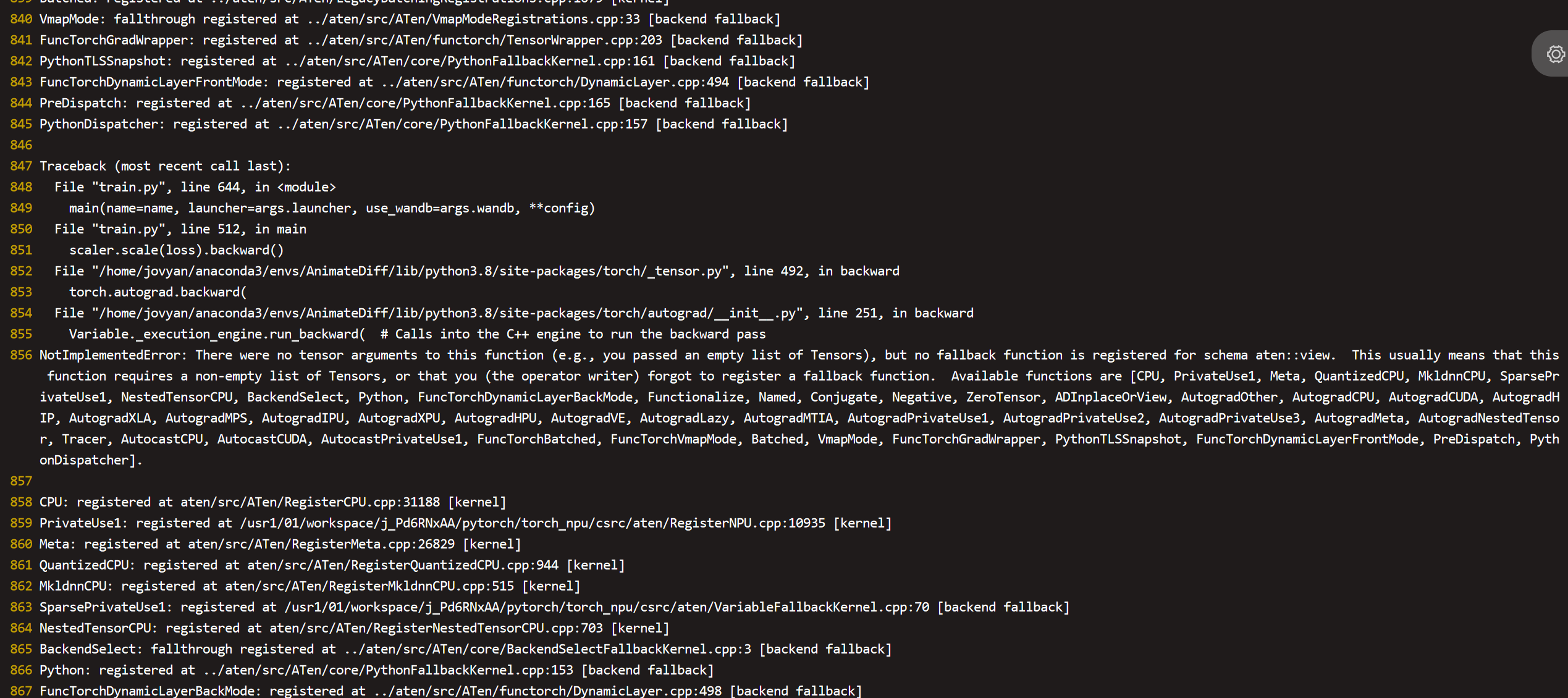
查看报错栈,找到错误函数算子,保存算子入参的tensor到本地,然后写一个单算子用例进行验证。由于错误在反向,我们需要先查看导致反向报错的正向算子是哪个,这里我们可以直接使用使用自动求导特性torch.autograd.detect.anomaly()将正反向包住,然后跑测看一下是否能看到前向的算子错误
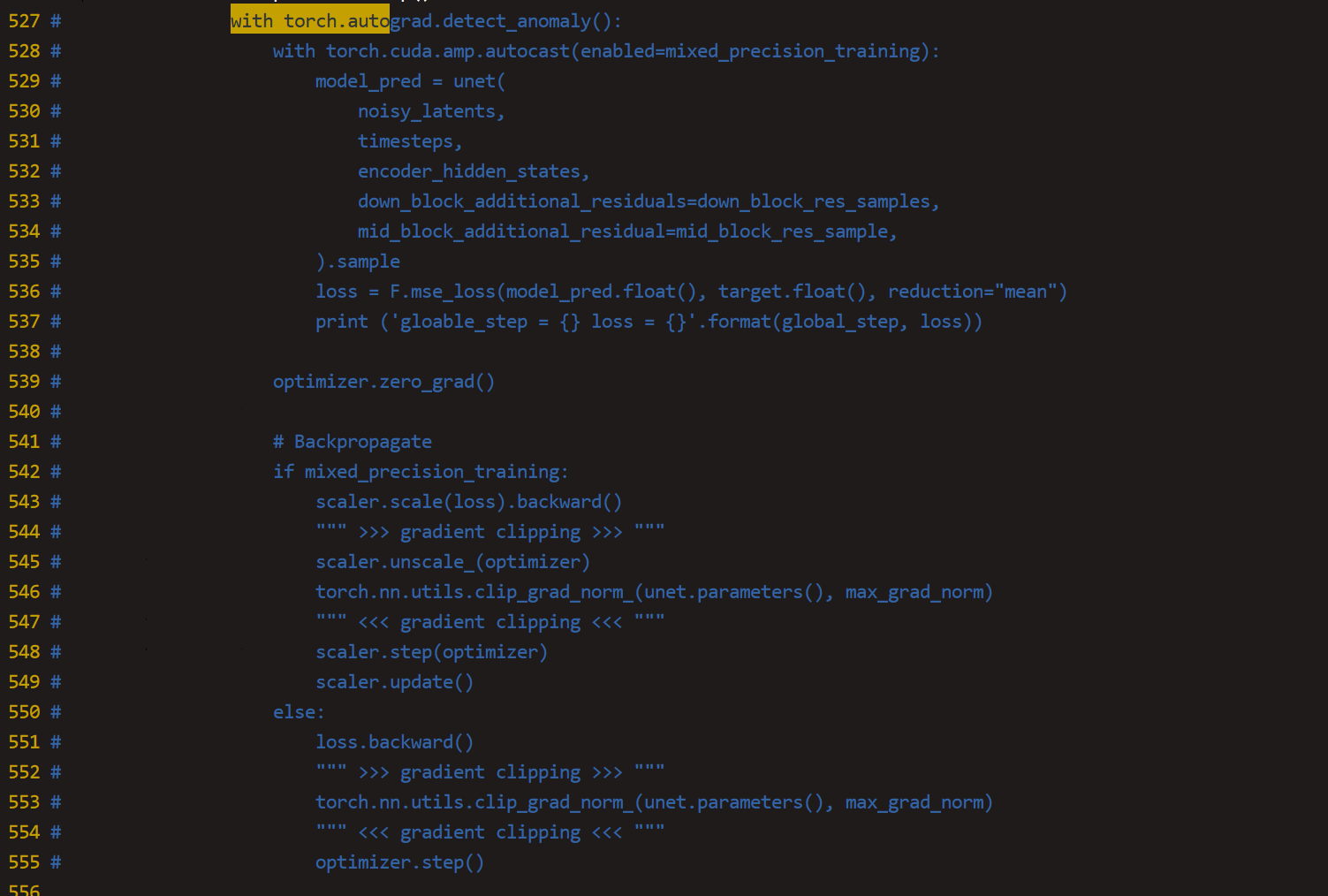
对于autograd,我们也可以全局设置,
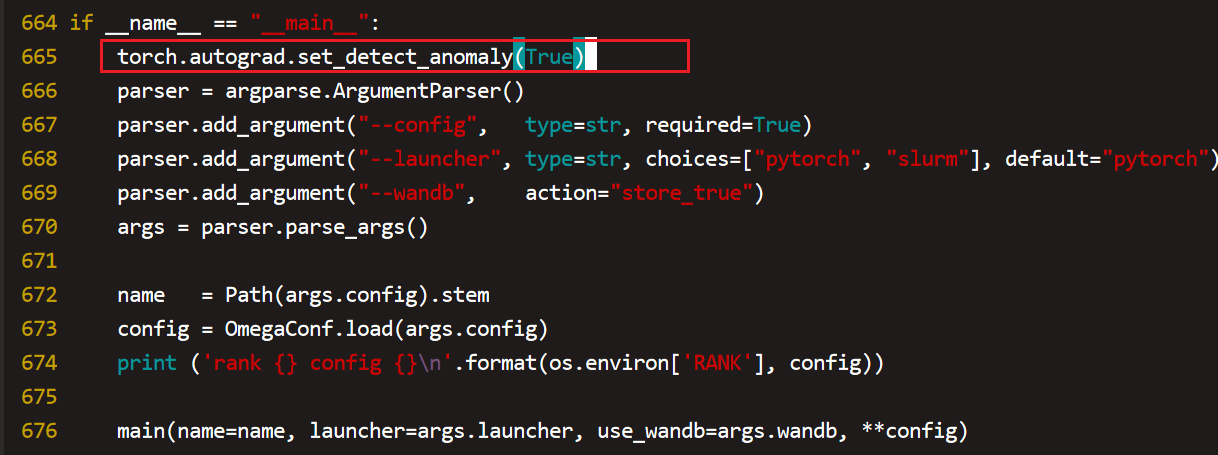
重新跑测之后我们可以看到导致反向报错的算子是torch.grad_norm了,
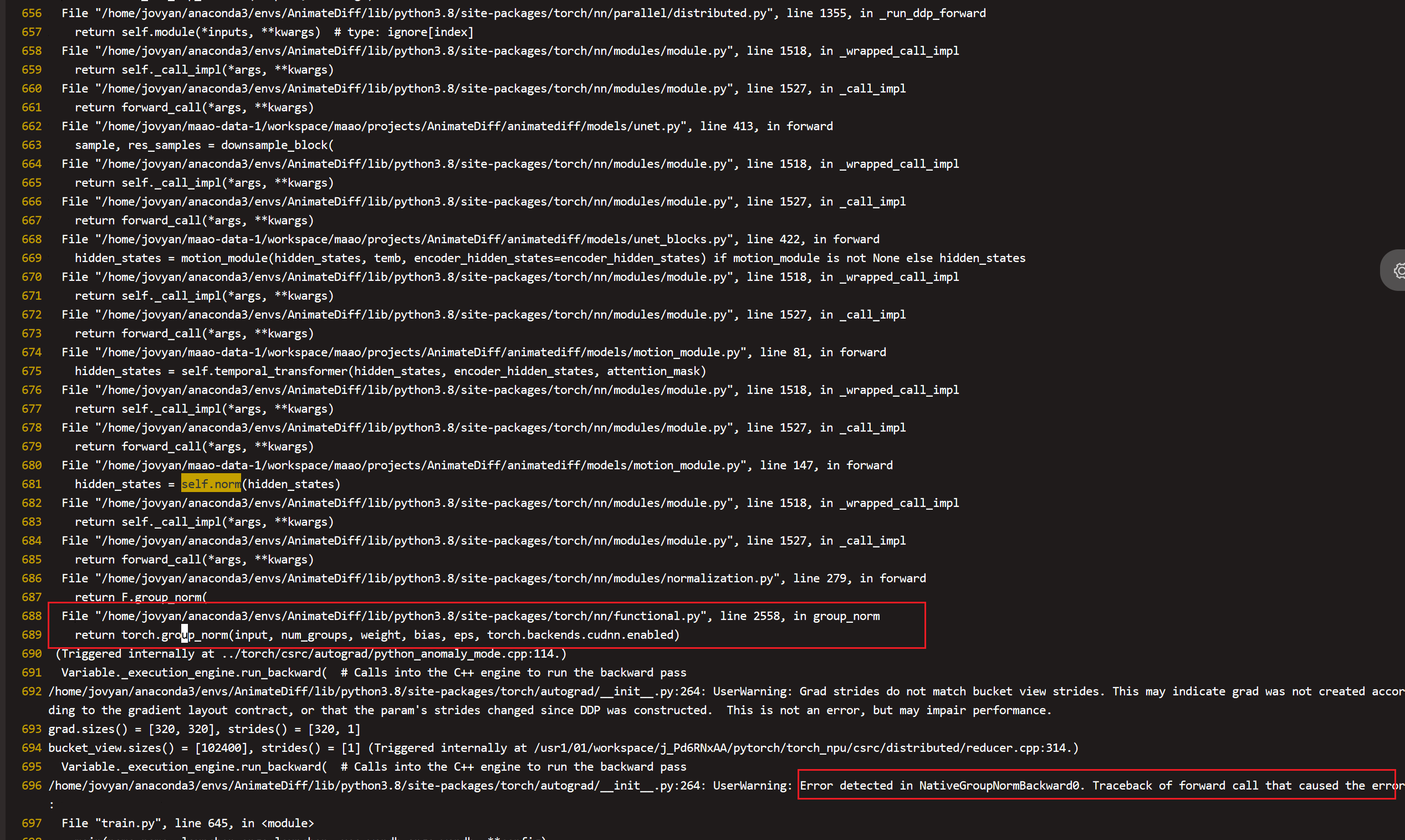
我们只需要保存入参几个tensor和记住其他几个基本类型的参数就可以构造单算子用例了
单算子用例
import torch
import torch_npu
from torch import nn
import sys
eps=float(sys.argv[1])
#inp=torch.load('32_input.pt',map_location=torch.device('cpu'))
inp=torch.load('32_{}_input.pt'.format(eps)).npu()
weight=torch.load('32_{}_weight.pt'.format(eps)).npu()
bias=torch.load('32_{}_bias.pt'.format(eps)).npu()
#norm=torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True).npu().half()
print(f"inp dtype {inp.dtype}")
print(f"weight dtype {weight.dtype}")
print(f"bias dtype {bias.dtype}")
print(torch.backends.cudnn.enabled)
print(inp.device)
print(weight.device)
print(bias.device)
x=torch.group_norm(inp.float(), 32, weight, bias, eps, torch.backends.cudnn.enabled).sum()
x.backward()
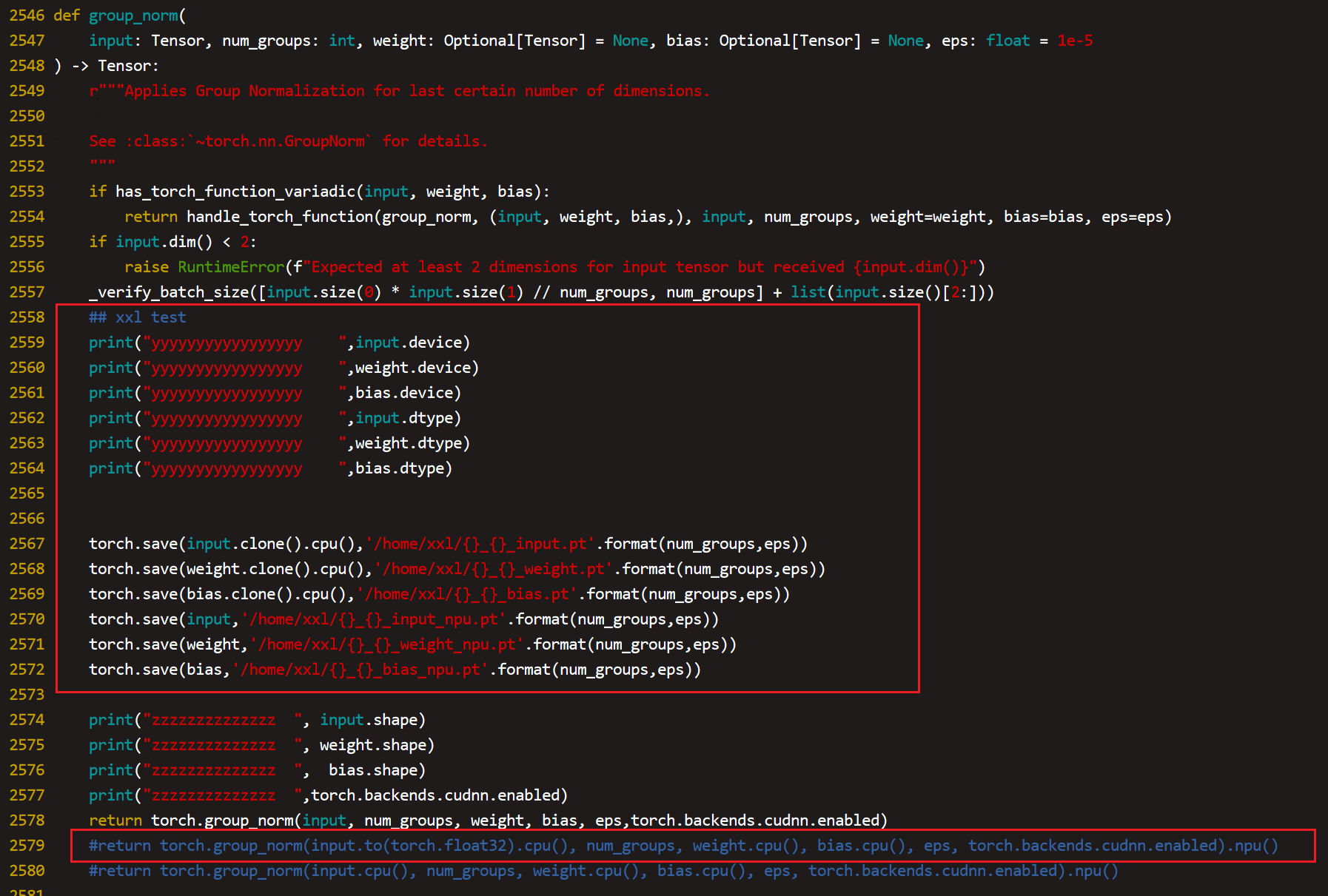
对于保存tensor之后加载tensor到npu上测试存在一个问题是无法加载npu格式的tensor,只能加载主动调用cpu()转为cpu格式再save的tensor,可能是这个原因导致单算子测试没有达到预期效果,但是我们基本确定是torch.group_norm的问题,于是我们直接反向验证整网中只把torch.group_norm算子放在cpu上跑,其他还是再npu上跑,如果能正常拉起能敲定该算子就是根因,
这里使用2579行测试groupnorm算子在cpu上计算能拉起,敲定groupnorm算子异常,于是和对应的owner对接就行了

其他: